
Tiki họ dùng java lâu rồi, đang có plan đổi qua golang đó, mà ko biết cụ thể thế nào và đã tới đâu. Nhưng mình nghĩ sẽ khó, do hệ thống business của mấy cty thương mại điện tử này là cực kỳ đồ sộ và phức cmn tạp.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
thảo luận Microservices and Cloud Native Group
- Thread starter RPG29
- Start date
gâu_
Đã tốn tiền
theo bạn một product thì khi nào cần áp dụng microservices :-?. Có nên build nó từ ban đầu không :-?
Nếu dự án mới thì theo mình nên build từ ban đầu luôn, thời điểm hiện tại thì tool cho microservices được trang bị tận răng hết rồi nên dùng luôn tiện hơn. Ban đầu chỉ cần tạo một template chuẩn thì việc tạo các service là nhanh chóng.
Deploy thì cứ đưa lên cloud rồi terraform + k8s thẳng tiến, môi trường dev với production cơ bản sẽ gần giống nhau, hoặc có thể là cùng trên 1 k8s cluster luôn.
mất quá nhiều effort so với build monolithic, nếu dư dả thì không sao, starup thì không nênNếu dự án mới thì theo mình nên build từ ban đầu luôn, thời điểm hiện tại thì tool cho microservices được trang bị tận răng hết rồi nên dùng luôn tiện hơn. Ban đầu chỉ cần tạo một template chuẩn thì việc tạo các service là nhanh chóng.
Deploy thì cứ đưa lên cloud rồi terraform + k8s thẳng tiến, môi trường dev với production cơ bản sẽ gần giống nhau, hoặc có thể là cùng trên 1 k8s cluster luôn.
gâu_
Đã tốn tiền
mất quá nhiều effort so với build monolithic, nếu dư dả thì không sao, starup thì không nên
Build microservices từ đầu so với build monolithic modularized sẵn thì công sức chẳng chênh nhau bao nhiêu đâu, còn mà build monolithic dạng một cục thì lỡ vài hôm mà sản phẩm thành công muốn scale cũng không được nhé, chưa kể lúc đó lãng phí chi phí cho resource. Ngày xưa người ta build sản phẩm từ thời microservices chưa phổ biến, tool tiếc chưa có nên mới phải build monolithic chứ bây giờ mà build từ đầu monolithic thì chẳng khác nào làm sản phẩm mà cứ tính sẵn đường không thành công nên user không nhiều.
Kinh nghiệm bản thân khi lv vs distributed system & microservice có mấy vấn để nổi bật:
1. Làm sao để chia tách service -> áp dụng DDD để giải quyết
2. Làm sao để scale các service -> áp dụng CQRS, đối vs từng domain sẽ có phần đọc (query) & phần ghi (command). phần đọc scale thoải mái, phần ghi thì không
3. Làm sao để giao tiếp giũa các service -> syncronous = rest api, gRPC,... hoặc asyncronous = message broker (kafka, rabbitmq...)
4. Làm sao để đồng bộ dữ liệu giũa các service -> explixit (viết code để handle trực tiếp), 2 phase commit, DB transaction log tails, event sourcing
achitect của 1 hệ thống là cái cốt lõi, chỉn chu từ đầu luôn luôn tốt hơn, effort bỏ ra thiết kế microservice ngay ban đầu chác chắn nhỏ hơn nhiều khi migrate 1 hệ thống monolithic -> microservice. Tất nhiên là trừ khi bạn ko muốn migtate từ monolithic -> microservice
1. Làm sao để chia tách service -> áp dụng DDD để giải quyết
2. Làm sao để scale các service -> áp dụng CQRS, đối vs từng domain sẽ có phần đọc (query) & phần ghi (command). phần đọc scale thoải mái, phần ghi thì không
3. Làm sao để giao tiếp giũa các service -> syncronous = rest api, gRPC,... hoặc asyncronous = message broker (kafka, rabbitmq...)
4. Làm sao để đồng bộ dữ liệu giũa các service -> explixit (viết code để handle trực tiếp), 2 phase commit, DB transaction log tails, event sourcing
achitect của 1 hệ thống là cái cốt lõi, chỉn chu từ đầu luôn luôn tốt hơn, effort bỏ ra thiết kế microservice ngay ban đầu chác chắn nhỏ hơn nhiều khi migrate 1 hệ thống monolithic -> microservice. Tất nhiên là trừ khi bạn ko muốn migtate từ monolithic -> microservice
MainOC
Senior Member
Cảm ơn chia sẻ của các bác.
Nhân đây em muốn hỏi một vấn đề như sau: Giả sử mình có 4 service A B C D. Khi có một request gửi tới A, thì A sẽ xử lý sau đó tiếp tục gửi 3 request tương ứng tới B, C và D. Cả B, C, D đều có thể fail, và nếu fail ít nhất 1 trong 3 service B C D thì phải rollback lại ở các service khác. Vậy trường hợp này mình nên thiết kế như thế nào cho hợp lý?
Nhân đây em muốn hỏi một vấn đề như sau: Giả sử mình có 4 service A B C D. Khi có một request gửi tới A, thì A sẽ xử lý sau đó tiếp tục gửi 3 request tương ứng tới B, C và D. Cả B, C, D đều có thể fail, và nếu fail ít nhất 1 trong 3 service B C D thì phải rollback lại ở các service khác. Vậy trường hợp này mình nên thiết kế như thế nào cho hợp lý?
Bạn wrap 1 cái transaction từ service A, giả sử các services giao tiếp thông qua message, khi các services B,C,D hoàn thành thì commit trans, còn 1 trong các services lỗi thì abort trans và thực hiện rollbackCảm ơn chia sẻ của các bác.
Nhân đây em muốn hỏi một vấn đề như sau: Giả sử mình có 4 service A B C D. Khi có một request gửi tới A, thì A sẽ xử lý sau đó tiếp tục gửi 3 request tương ứng tới B, C và D. Cả B, C, D đều có thể fail, và nếu fail ít nhất 1 trong 3 service B C D thì phải rollback lại ở các service khác. Vậy trường hợp này mình nên thiết kế như thế nào cho hợp lý?
cái này thường sẽ có 2 pattern để xử lý là `2pc (two-phase commit) ` và `Saga`
Kh
2. Không nhưng nên dùng DDD để phân chia rạch ròi và dùng layered architecture để thiết kế phần mềm sau này có migrate qua thì đỡ công viết lại nhiều
1. Khi nó to, phát triển ra là biết có vài k users đang chờ, cần tính toán lớn, hoặc nhiều bộ phận tính toán độc lập.theo bạn một product thì khi nào cần áp dụng microservices :-?. Có nên build nó từ ban đầu không :-?
2. Không nhưng nên dùng DDD để phân chia rạch ròi và dùng layered architecture để thiết kế phần mềm sau này có migrate qua thì đỡ công viết lại nhiều
Microservices có phải chỉ có thiết kế không đâu, còn set úp, dev, test , minitoring và deploy nữa. Cái nào nó cũng yêu cầu vượt trội so với mônlithic. Đó là lý do tại sao các startup muốn ra sp nhanh hay xài mônlithicKinh nghiệm bản thân khi lv vs distributed system & microservice có mấy vấn để nổi bật:
1. Làm sao để chia tách service -> áp dụng DDD để giải quyết
2. Làm sao để scale các service -> áp dụng CQRS, đối vs từng domain sẽ có phần đọc (query) & phần ghi (command). phần đọc scale thoải mái, phần ghi thì không
3. Làm sao để giao tiếp giũa các service -> syncronous = rest api, gRPC,... hoặc asyncronous = message broker (kafka, rabbitmq...)
4. Làm sao để đồng bộ dữ liệu giũa các service -> explixit (viết code để handle trực tiếp), 2 phase commit, DB transaction log tails, event sourcing
achitect của 1 hệ thống là cái cốt lõi, chỉn chu từ đầu luôn luôn tốt hơn, effort bỏ ra thiết kế microservice ngay ban đầu chác chắn nhỏ hơn nhiều khi migrate 1 hệ thống monolithic -> microservice. Tất nhiên là trừ khi bạn ko muốn migtate từ monolithic -> microservice
RPG29
Đã tốn tiền
Cảm ơn chia sẻ của các bác.
Nhân đây em muốn hỏi một vấn đề như sau: Giả sử mình có 4 service A B C D. Khi có một request gửi tới A, thì A sẽ xử lý sau đó tiếp tục gửi 3 request tương ứng tới B, C và D. Cả B, C, D đều có thể fail, và nếu fail ít nhất 1 trong 3 service B C D thì phải rollback lại ở các service khác. Vậy trường hợp này mình nên thiết kế như thế nào cho hợp lý?
Trên lý thuyết thì có thể dùng 2-Phases Commit (2PC) hoặc Saga nhưng mà thực tế thì nên cố gắng tránh depend giữa các service vì hiện thực 2PC hoặc Saga không dễ.
Cái nữa depend giữa các service đi ngược lại lợi ích của microservices là isolation, independent và làm tăng độ phức tạp cho việc phát triển, triển khai, vận hành...
Có một số thiết kế họ cho thêm component gọi là aggregation service nằm phía trên các microservices nhỏ để combine kết quả trả về từ các services, mình không thích cách thiết kế này vì nó làm tăng độ phức tạp rất nhiều.
Last edited:
theo yêu cầu của bạn kia đưa ra thì phải thiết kế thế thôiTrên lý thuyết thì có thể dùng 2-Phases Commit (2PC) hoặc Saga nhưng mà thực tế thì nên cố gắng tránh depend giữa các service vì hiện thực 2PC hoặc Saga không dễ.
Cái nữa depend giữa các service đi ngược lại lợi ích của microservices là isolation, independent và làm tăng độ phức tạp cho việc phát triển, triển khai, vận hành...
Có một số thiết kế họ cho thêm component gọi là aggregation service nằm phía trên các microservices nhỏ để combine kết quả trả về từ các services, mình không thích cách thiết kế này vì nó làm tăng độ phức tạp rất nhiều.

gâu_
Đã tốn tiền
Có một số thiết kế họ cho thêm component gọi là aggregation service nằm phía trên các microservices nhỏ để combine kết quả trả về từ các services, mình không thích cách thiết kế này vì nó làm tăng độ phức tạp rất nhiều.
mình thì ngược lại thích cái pattern Aggregator này, cơ bản sẽ làm cho cái service này stateless, khác biệt so với các stateful service (service phụ thuộc datasource), mà stateless thì scale dễ hơn, có cái Aggregator thì ở các stateful service chỉ cần expose ra các function cơ bản thôi
deothieuhiep
Senior Member
tôi mới build forum cho ae lập trình mong ae vào ủng hộ và trải nghiệmThấy nhiều bác đang làm việc với Microservices và Cloud Native nên em lập topic này để chia sẻ kinh nghiệm và có chỗ cho mọi người chém.
Microservices và Cloud Native là chủ đề rất rộng nên em sẽ từ từ chia nhỏ nó ra thành từng mục cho mọi người dễ follow.
Những cái em chia sẻ hầu hết là kinh nghiệm cá nhân khi triển khai và những gì em nghiên cứu được nên sẽ có đúng có sai, các bác cứ gạch nhiệt tình.
Về ngôn ngữ lập trình thì trước giờ em từng làm việc với Java, Python, PHP và mới đây là Go cho nên em sẽ trả lời cụ thể nếu liên quan còn với những ngôn ngữ khác thì em chỉ có thể tư vấn giải pháp chung chung.
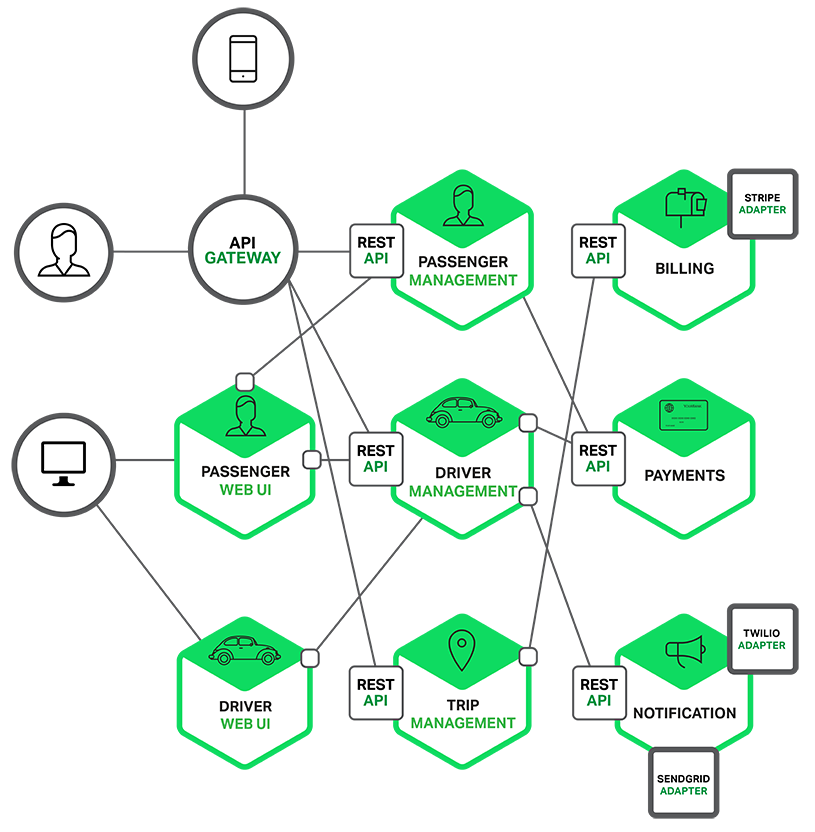
Giới thiệu sơ qua với các bác về kinh nghiệm làm việc với Microservices và sau này là Cloud Native của em.
Em bắt đầu nghiên cứu xây dựng hệ thống lớn và scalability từ khoảng cuối năm 2012, thời điểm đó ở VN vẫn chưa thấy có ai nhắc tới từ Microservices. Thời điểm đó các tài liệu về xây dựng hệ thống, vận hành, scale... không nhiều và hầu hết em đọc là từ http://highscalability.com. Thằng này nó đưa đẩy dẫn lối cho em từ lúc đó, đam mê nghiên cứu kiến trúc hệ thống.
Khoảng đầu 2013 thì em đi làm chính thức ở một dự án mà bây giờ là một cty thương mại điện tử top của VN. Lần đầu tiên mới được tiếp xúc với các quy trình phát triển, triển khai, vận hành, scale, system... trong thực tế. Sau đó thì em nhảy lóc cóc mấy công ty cho đến khi bắt đầu tham gia một dự án mà em là người trực tiếp thiết kế vận hành nó.
Khởi đầu thì hệ thống em triển khai nó viết bằng PHP 5.6, MySQL 5.6. Nó là một cục monolithic to bự viết bằng Symfony 2.x, chạy trên nền PHP-FPM, Nginx, CentOS 6.x từ khoảng giữa năm 2014.
Hồi mới start cũng chỉ mang tính chất prototype nên mọi thứ không được chú trọng thiết kế cho lắm, miễn sao release nhanh ra chạy lấy feedback là được rồi.
// TODO

bachhacden
Senior Member
Nhớ hồi xưa làm cái hệ thống cần scalable mà chưa có đồ chơi như giờ. Setup on-premise đủ thứ load balancing, failover, monitor tè le hột dưa các kiểu mệt sml.
Giờ thì đủ cả tool toy các kiểu, búng tay vài cái là lên đỉnh luôn.
Giờ thì đủ cả tool toy các kiểu, búng tay vài cái là lên đỉnh luôn.
Cách mình hay dùng là sau khi svc A xử lý xong sẽ publish 1 event lên 1 topic ở message broker, 3 svc còn lại consume event từ topic đó và xử lý. Đồng thời có 1 dead letter queue đi kèm vs topic đó, cả 4 svc đều subcribe cái DLQ này, khi 1 trong 3 svc fail, nó sẽ publish 1 event lên DLQ và cả 3 còn còn lại sẽ nhận dc và rollbackCảm ơn chia sẻ của các bác.
Nhân đây em muốn hỏi một vấn đề như sau: Giả sử mình có 4 service A B C D. Khi có một request gửi tới A, thì A sẽ xử lý sau đó tiếp tục gửi 3 request tương ứng tới B, C và D. Cả B, C, D đều có thể fail, và nếu fail ít nhất 1 trong 3 service B C D thì phải rollback lại ở các service khác. Vậy trường hợp này mình nên thiết kế như thế nào cho hợp lý?
MainOC
Senior Member
Bạn wrap 1 cái transaction từ service A, giả sử các services giao tiếp thông qua message, khi các services B,C,D hoàn thành thì commit trans, còn 1 trong các services lỗi thì abort trans và thực hiện rollback
cái này thường sẽ có 2 pattern để xử lý là `2pc (two-phase commit) ` và `Saga`
Trên lý thuyết thì có thể dùng 2-Phases Commit (2PC) hoặc Saga nhưng mà thực tế thì nên cố gắng tránh depend giữa các service vì hiện thực 2PC hoặc Saga không dễ.
Cái nữa depend giữa các service đi ngược lại lợi ích của microservices là isolation, independent và làm tăng độ phức tạp cho việc phát triển, triển khai, vận hành...
Có một số thiết kế họ cho thêm component gọi là aggregation service nằm phía trên các microservices nhỏ để combine kết quả trả về từ các services, mình không thích cách thiết kế này vì nó làm tăng độ phức tạp rất nhiều.
Cách mình hay dùng là sau khi svc A xử lý xong sẽ publish 1 event lên 1 topic ở message broker, 3 svc còn lại consume event từ topic đó và xử lý. Đồng thời có 1 dead letter queue đi kèm vs topic đó, cả 4 svc đều subcribe cái DLQ này, khi 1 trong 3 svc fail, nó sẽ publish 1 event lên DLQ và cả 3 còn còn lại sẽ nhận dc và rollback
Thank các thím, để mình tìm hiểu thêm về các pattern này.
Mà ý thím @RPG29 nói vụ tránh depend giữa các service là sao nhỉ, mình chưa hiểu rõ lắm?
lợi ích của ms là isolation, independent nếu thím đưa bài toán thế kia thì services A sẽ phụ thuộc vào 3 services B,C,DThank các thím, để mình tìm hiểu thêm về các pattern này.
Mà ý thím @RPG29 nói vụ tránh depend giữa các service là sao nhỉ, mình chưa hiểu rõ lắm?
Đúng ra thì A là A mà B là B, thằng nào failed thì lại có short circuit riêng
Last edited:
MainOC
Senior Member
Giờ mình ví dụ usecase như thế này: A là OrderService, B là BalanceService (quản lý số dư tài khoản), C là StorageService (quản lý hàng hoá trong kho), đại loại như thế (B hay C có thể là third-party service). Khi A process một order, thì nó phải gọi qua B để update số dư, và gọi qua C để update số lượng. Như vậy thì có gọi là A phụ thuộc vào B không nhỉ? Và nếu để không phụ thuộc thì trong trường hợp này mình nên thiết kế như thế nào cho hợp lý nhỉ?lợi ích của ms là isolation, independent nếu thím đưa bài toán thế kia thì services A sẽ phụ thuộc vào 3 services B,C,D
Đúng ra thì A là A mà B là B, thằng nào failed thì lại có short circuit riêng
p/s: Mấy cái mô hình micro-services này trước giờ mình toàn tự vẽ ra rồi code demo chơi chơi chứ chưa có dịp apply vô product thực tế nào nên hơi mù mờ, mong các thím chỉ giáo thêm

Similar threads
- Replies
- 0
- Views
- 158
- Replies
- 0
- Views
- 65
- Replies
- 2
- Views
- 519
- Replies
- 15
- Views
- 884
- Replies
- 7
- Views
- 385