
hiepgia
Đã tốn tiền
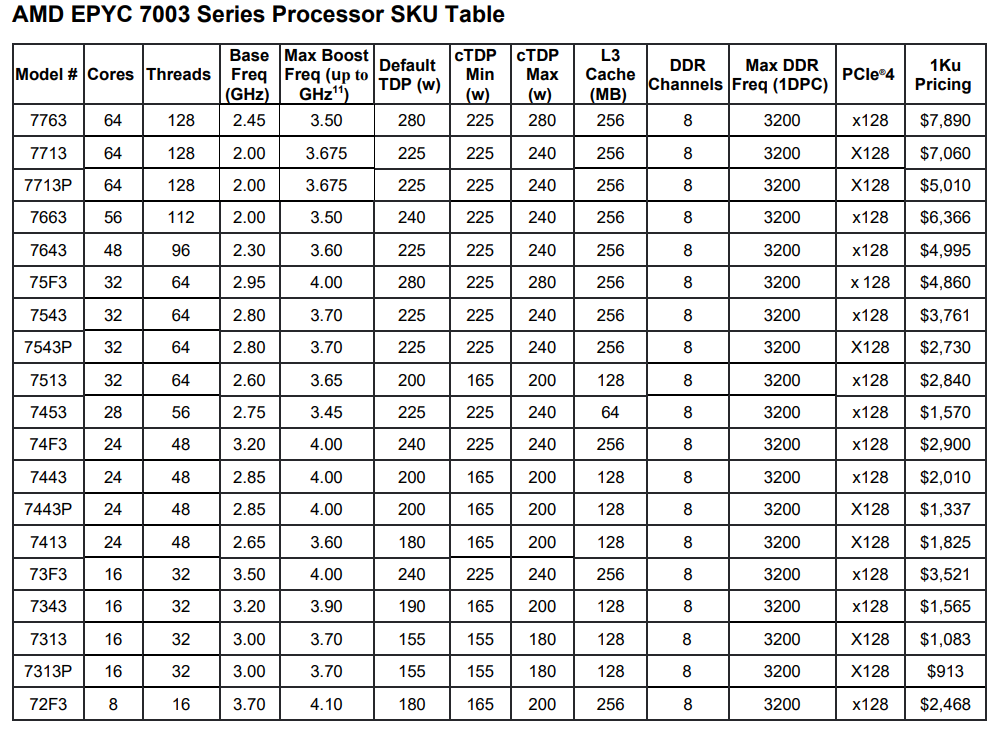
EPYC "Rome" 7002 là một trong những CPU máy chủ mạnh nhất của hiện tại. Nhưng AMD vẫn tiếp tục không ngừng nghỉ để tiếp tục mang đến những sản phẩm mới. EPYC "Milan" 7003 đã sẵn sàng để ra mắt mang với những cải thiện để tăng sức mạnh cũng như cạnh tranh. AMD đã làm rất tốt với sản phẩm EPYC "Rome" 7002 với thiết kế độc đáo MCM gồm cIO và cCD giúp cải thiện đáng kể hiệu năng bộ nhớ, khả năng xử lý cũng nhu chú trọng vào bảo mật và điện năng tiêu thụ. EPYC "Milan" 7003 tiếp tục kế thừa thiết kế đó nhưng mang lại nhiều cải tiến ở sâu bên trong kiến trúc Zen 3 nâng cấp từ Zen 2.
Zen 2 lên Zen 3 có điểm gì mới?
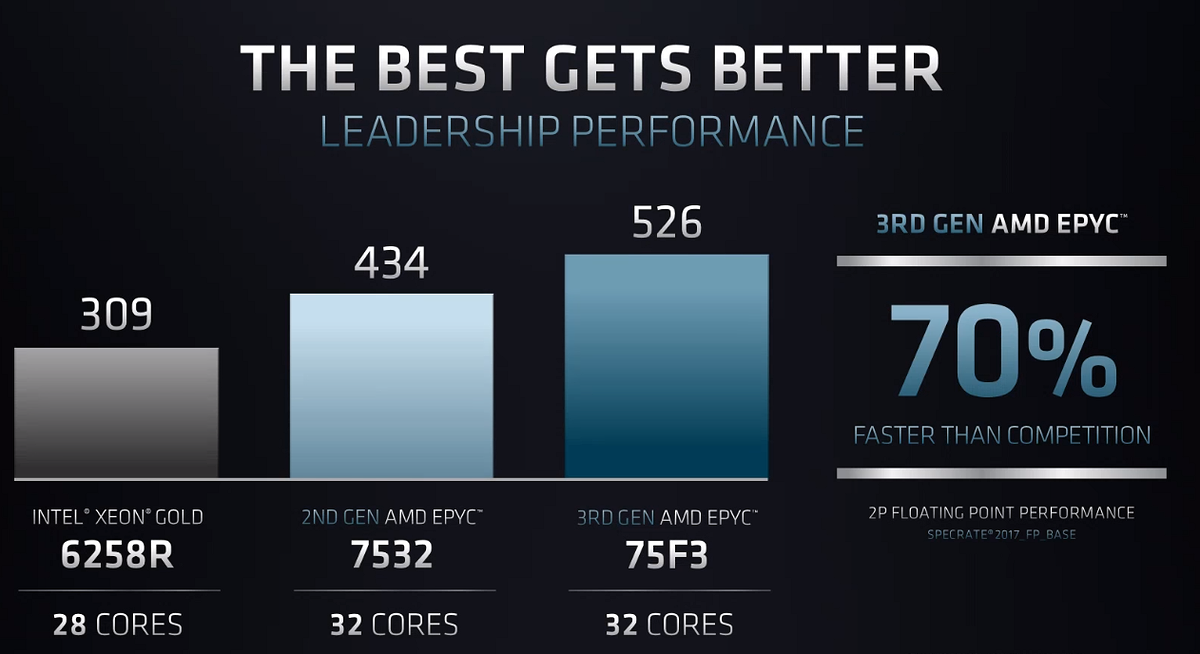
Hiệu năng thực thi hoàn toàn có thể dự đoán được, nhờ vào những thay đổi sâu bên trong kiến trúc, chúng ta sẽ nói về điều này ở phần sau. Và tiếp tục lời hứa về IPC tăng lên sau mỗi thế hệ, chúng ta đã biết rằng Zen 3 có IPC hơn Zen 2 đến 19% nhờ danh sách dài những những cải thiện bên trong kiến trúc. Nhờ hiệu năng cải thiện với Zen 3, hiện EPYC "Milan" 7003 đã mang lại hiệu năng gấp đôi đối thủ trong các benchmark tiêu chuẩn công nghiệp như SPECjbb 2015, SPECRate 2017 Int và SPECRate 2017 FP. Bảo mật cũng được cải thiện với việc sửa hoàn toàn các lỗi về kiến trúc kèm thêm các tính năng bảo mật mới giúp chúng ta hoàn toàn yên tâm về dữ liệu được lưu trữ hay xử lý.

Kiến trúc Zen 3 là một kiến trúc rất mạnh.
Chúng ta sẽ đi vào chi tiết của kiến trúc này để xem những cải thiện này:
Bộ dự đoán lệnh (Brand Predictor) và Bộ đệm lệnh (OpCache)
Đây là thành phần giúp phân tích, tìm và nạp trước lệnh/dữ liệu vào bộ nhớ đệm trước để giảm độ trễ. AMD hiện sử dụng thiết kế TAGE từ Zen 2 để tăng độ chính xác của dự đoán lệnh/dữ liệu. Nhưng ở Zen 3 chúng ta có bộ đệm dự đoán đích ở cache L1 (Brand Target Buffer - Cache L1 BTB) lớn hơn gấp đôi từ 512 mục lên 1024 mục và cân bằng lại thiết kế bộ đệm dự đoán đích Cache L2 giảm từ 7k mục xuống 6.5 mục. Mảng mục tiêu gián tiếp (Indirect target array - ITA) cũng được tăng từ 1024 mục lên 1536 mục. Nếu dự đoán sai, thiết kế mới cũng giảm đáng kể độ trễ để lấy được đúng luồng dữ liệu. AMD cũng cho biết rằng không có bong bóng trong hầu hết các dự đoán trước nhờ băng thông cao hơn gấp đôi, nhờ thế có thể lấp đầy các bong bóng trước khi chạm đến trong giai đoạn thực thi. Trong trường hợp bong bóng dự đoán lệnh được lấp đầy thì có thể làm trì trệ việc thực thi khiến giảm hiệu năng. Bộ đệm lệnh nhanh hơn: Lấy lệnh và chuyển ống lệnh nhanh hơn so với Zen 2. Ở Zen 2 lấy 8 chỉ lệnh/chu kỳ, với Zen 3 lấy 8 Macro (1 macro = 1 tập chỉ lệnh) hoặc 8 lệnh.
Tóm lại cho các bạn dễ hiểu: Bộ dự đoán lệnh ở Zen 3 hiệu quả hơn giúp lấy lệnh, dữ liệu đưa vào sẵn bộ đệm lệnh -> Nhân xử lý có sẵn dữ liệu để xử lý liên tục, không phải ngồi chờ dữ liệu nhờ đó tăng hiệu năng.
Bộ nhớ đệm cấp 1 (Cache L1) tối ưu hơn
So với Zen 2, bộ nhớ đệm cấp 1 vẫn là 32KB 8-way nhưng AMD đã cải thiện đáng kể việc sử dụng nó bằng cách lấy dữ liệu từ bộ nhớ đệm cấp 2 hiệu quả và liên tục hơn trước khi được sử dụng ở bộ nhớ đệm cấp 1.
Cải thiện ở phần thực thi:
Chúng ta xét đến phần thực thi số nguyên(Integer Execution) Ở phần giải mã (Decode Stage), AMD thiết kế 4-Wide Scheduler thay vì 7-Wide Scheduler, thiết kế rộng hơn có thể khiến độ trễ ống lệnh cao hơn đẩy thời gian thực thi dài hơn. Thiết kế này là khá cân bằng tương tự như Sunny Cove và Willow Cove. Sang đến phần thực thi, AMD duy trì kiến trúc 6-Wide, nhưng nạp/lưu nhanh hơn. (1+ nạp, 1+ lưu). Việc nạp/lưu giờ rất "uyển chuyển" thay vì fix như ở Zen 2. Kiến trúc Zen 3 có 10 bộ xuất lệnh mỗi chu kỳ thay vì 7 ở Zen 2.
Tóm lại cho các bạn dễ hiểu: Thực thi số nguyên ở Zen 3 được AMD tối ưu giúp xử lý uyển chuyển, rộng hơn và nhanh hơn.
Chúng ta xét đến phần thực thi số thực (Floating Point Execution) Ở phần số thực, chúng ta có kiến trúc rộng hơn với 6 Wide nhưng bộ ghi vẫn là 256 bit ứng với AVX2. FMAC (fused multiply–accumulate) được thực thi với độ trễ thấp hơn (-1 chu kỳ). Hỗ trợ tốt hơn cho Machine Learning với khả năng xử lý INT8 nhanh hơn x2 với 2 bộ F2I. Đây là kiến trúc xử lý số thực nhanh nhất của AMD từ trước đến giờ. Theo mình AMD đã làm một kiến trúc cực kì cân bằng từ việc gửi lệnh xuống thực thi (6 Macro Ops / chu kỳ) -> Thực thi đều là 6 Wide cho cả Int/FP giúp tối ưu điện năng tiêu thụ và cả độ trễ.
 Kiến trúc bộ đệm cũng chứng kiến thay đổi quan trọng ở bộ nhớ đệm cấp 3.
Kiến trúc bộ đệm cũng chứng kiến thay đổi quan trọng ở bộ nhớ đệm cấp 3.

Bộ nhớ đệm cấp 3 ở Zen 3 lớn chỉ gồm 1 cụm 32MB giúp các ứng dụng có thể lưu trữ dữ liệu để xử lý nhiều hơn, chia sẻ dữ liệu nhanh hơn giảm độ trễ giữa các nhân trong cùng 1 CCX.
Zen 3 cũng giới thiệu thêm nhiều lệnh mới giúp cải thiện bảo mật, thực thi.

Bảo mật chống Spectre từ phần cứng.

Zen 2 lên Zen 3 có điểm gì mới?
Hiệu năng thực thi hoàn toàn có thể dự đoán được, nhờ vào những thay đổi sâu bên trong kiến trúc, chúng ta sẽ nói về điều này ở phần sau. Và tiếp tục lời hứa về IPC tăng lên sau mỗi thế hệ, chúng ta đã biết rằng Zen 3 có IPC hơn Zen 2 đến 19% nhờ danh sách dài những những cải thiện bên trong kiến trúc. Nhờ hiệu năng cải thiện với Zen 3, hiện EPYC "Milan" 7003 đã mang lại hiệu năng gấp đôi đối thủ trong các benchmark tiêu chuẩn công nghiệp như SPECjbb 2015, SPECRate 2017 Int và SPECRate 2017 FP. Bảo mật cũng được cải thiện với việc sửa hoàn toàn các lỗi về kiến trúc kèm thêm các tính năng bảo mật mới giúp chúng ta hoàn toàn yên tâm về dữ liệu được lưu trữ hay xử lý.
Kiến trúc Zen 3 là một kiến trúc rất mạnh.
Chúng ta sẽ đi vào chi tiết của kiến trúc này để xem những cải thiện này:
Bộ dự đoán lệnh (Brand Predictor) và Bộ đệm lệnh (OpCache)
Đây là thành phần giúp phân tích, tìm và nạp trước lệnh/dữ liệu vào bộ nhớ đệm trước để giảm độ trễ. AMD hiện sử dụng thiết kế TAGE từ Zen 2 để tăng độ chính xác của dự đoán lệnh/dữ liệu. Nhưng ở Zen 3 chúng ta có bộ đệm dự đoán đích ở cache L1 (Brand Target Buffer - Cache L1 BTB) lớn hơn gấp đôi từ 512 mục lên 1024 mục và cân bằng lại thiết kế bộ đệm dự đoán đích Cache L2 giảm từ 7k mục xuống 6.5 mục. Mảng mục tiêu gián tiếp (Indirect target array - ITA) cũng được tăng từ 1024 mục lên 1536 mục. Nếu dự đoán sai, thiết kế mới cũng giảm đáng kể độ trễ để lấy được đúng luồng dữ liệu. AMD cũng cho biết rằng không có bong bóng trong hầu hết các dự đoán trước nhờ băng thông cao hơn gấp đôi, nhờ thế có thể lấp đầy các bong bóng trước khi chạm đến trong giai đoạn thực thi. Trong trường hợp bong bóng dự đoán lệnh được lấp đầy thì có thể làm trì trệ việc thực thi khiến giảm hiệu năng. Bộ đệm lệnh nhanh hơn: Lấy lệnh và chuyển ống lệnh nhanh hơn so với Zen 2. Ở Zen 2 lấy 8 chỉ lệnh/chu kỳ, với Zen 3 lấy 8 Macro (1 macro = 1 tập chỉ lệnh) hoặc 8 lệnh.
Tóm lại cho các bạn dễ hiểu: Bộ dự đoán lệnh ở Zen 3 hiệu quả hơn giúp lấy lệnh, dữ liệu đưa vào sẵn bộ đệm lệnh -> Nhân xử lý có sẵn dữ liệu để xử lý liên tục, không phải ngồi chờ dữ liệu nhờ đó tăng hiệu năng.
Bộ nhớ đệm cấp 1 (Cache L1) tối ưu hơn
So với Zen 2, bộ nhớ đệm cấp 1 vẫn là 32KB 8-way nhưng AMD đã cải thiện đáng kể việc sử dụng nó bằng cách lấy dữ liệu từ bộ nhớ đệm cấp 2 hiệu quả và liên tục hơn trước khi được sử dụng ở bộ nhớ đệm cấp 1.
Cải thiện ở phần thực thi:
Chúng ta xét đến phần thực thi số nguyên(Integer Execution) Ở phần giải mã (Decode Stage), AMD thiết kế 4-Wide Scheduler thay vì 7-Wide Scheduler, thiết kế rộng hơn có thể khiến độ trễ ống lệnh cao hơn đẩy thời gian thực thi dài hơn. Thiết kế này là khá cân bằng tương tự như Sunny Cove và Willow Cove. Sang đến phần thực thi, AMD duy trì kiến trúc 6-Wide, nhưng nạp/lưu nhanh hơn. (1+ nạp, 1+ lưu). Việc nạp/lưu giờ rất "uyển chuyển" thay vì fix như ở Zen 2. Kiến trúc Zen 3 có 10 bộ xuất lệnh mỗi chu kỳ thay vì 7 ở Zen 2.
Tóm lại cho các bạn dễ hiểu: Thực thi số nguyên ở Zen 3 được AMD tối ưu giúp xử lý uyển chuyển, rộng hơn và nhanh hơn.
Chúng ta xét đến phần thực thi số thực (Floating Point Execution) Ở phần số thực, chúng ta có kiến trúc rộng hơn với 6 Wide nhưng bộ ghi vẫn là 256 bit ứng với AVX2. FMAC (fused multiply–accumulate) được thực thi với độ trễ thấp hơn (-1 chu kỳ). Hỗ trợ tốt hơn cho Machine Learning với khả năng xử lý INT8 nhanh hơn x2 với 2 bộ F2I. Đây là kiến trúc xử lý số thực nhanh nhất của AMD từ trước đến giờ. Theo mình AMD đã làm một kiến trúc cực kì cân bằng từ việc gửi lệnh xuống thực thi (6 Macro Ops / chu kỳ) -> Thực thi đều là 6 Wide cho cả Int/FP giúp tối ưu điện năng tiêu thụ và cả độ trễ.
Bộ nhớ đệm cấp 3 ở Zen 3 lớn chỉ gồm 1 cụm 32MB giúp các ứng dụng có thể lưu trữ dữ liệu để xử lý nhiều hơn, chia sẻ dữ liệu nhanh hơn giảm độ trễ giữa các nhân trong cùng 1 CCX.
Zen 3 cũng giới thiệu thêm nhiều lệnh mới giúp cải thiện bảo mật, thực thi.
Bảo mật chống Spectre từ phần cứng.
Last edited:


















 fiji, new zealand
fiji, new zealand