
guyfawkes11
Junior Member
Plan for what it is difficult while it is easy, do what is great while it is small
― Sun Tzu, The Art of War
Tại sao sử dụng dữ liệu?
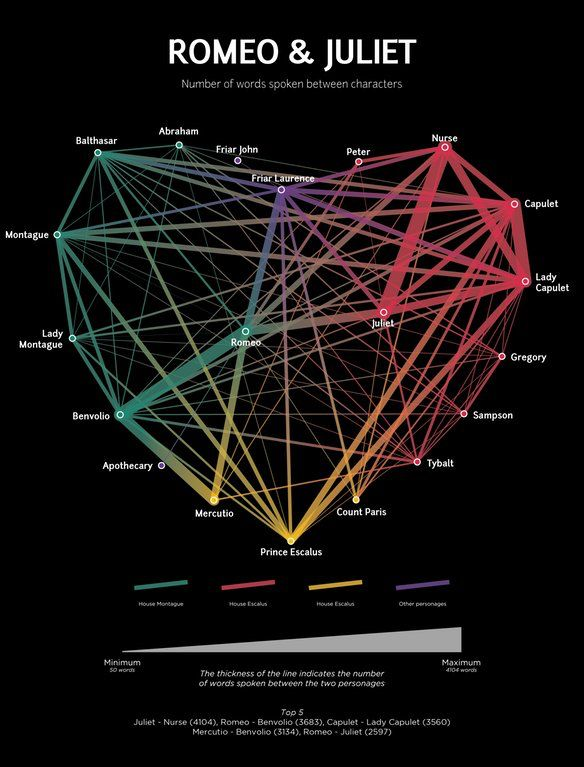 Dữ liệu đang làm được rất nhiều thứ: Thật kì diệu phải không nào, khi trực quan hóa số từ hội thoại của các nhân vật với nhau trong tiểu thuyết Romeo & Juliet sắp xếp theo các nhà là một hình trái tim (màu đỏ là House Capulet, tác giả bị lặp House Escalus).
Dữ liệu đang làm được rất nhiều thứ: Thật kì diệu phải không nào, khi trực quan hóa số từ hội thoại của các nhân vật với nhau trong tiểu thuyết Romeo & Juliet sắp xếp theo các nhà là một hình trái tim (màu đỏ là House Capulet, tác giả bị lặp House Escalus).
Quay trở lại với bóng đá thôi nào, dữ liệu là nguồn tài nguyên cực kỳ hữu ích cho các nhà tuyển trạch viên. Nó có thể cung cấp thông tin chi tiết mà bạn có thể không biết. Nếu bạn được yêu cầu nêu tên 3 trong số những hậu vệ cánh xuất sắc nhất ở National League (giải hạng 5 ở Anh) dưới 26 tuổi thì bạn có thể sẽ gặp khó khăn, nhưng với nguồn dữ liệu chất lượng và sử dụng tốt dữ liệu đó thì mọi việc trở nên dễ dàng hơn rất nhiều.
Bạn có thể nhanh chóng xây dựng danh sách cầu thủ phù hợp với mục tiêu tìm kiếm bằng cách sử dụng phân tích dữ liệu. Điều này có thể tiết kiệm rất nhiều thời gian để "xem giò" các cầu thủ, vì bạn đã có một danh sách chi tiết cấu thủ nào nên theo dõi, nó làm cho toàn bộ quá trình được "cô đặc" và hiệu quả hơn.
Lợi ích khác của việc sử dụng dữ liệu là nó giúp loại bỏ rất nhiều thành kiến. Các tuyển trạch viên có thể mắc phải những thành kiến này mà không nhận ra, họ có thể loại bỏ một cầu thủ dựa trên cách họ di chuyển, mặc dù cầu thủ đó có kết quả rất tốt.
Dữ liệu thì không mắc phải lỗi này vì nó không bị ảnh hưởng bởi cảm xúc. Tuy nhiên, các thành kiến có thể được xây dựng trong phân tích dữ liệu. Dữ liệu không bị sai lệch nhưng nhà phân tích dữ liệu có thể bị sai lệch.
Vì những lý do trên, tôi quyết định tạo ra một công cụ giúp tôi có cái nhìn "sâu hơn" về "phong cách" của một cầu thủ, điểm mạnh, điểm yếu của họ và cầu thủ nào phù hợp nhất với "phong cách" đó.
Phương pháp đánh giá
Quá trình xây dựng công cụ này là chia cầu thủ vào các vị trí khác nhau, sau đó chia họ thành nhiều "phong cách" khác nhau cho vị trí đó. Các vị trí và "phong cách" được hiển thị bên dưới:

Một trong những mục tiêu chính khi xây dựng công cụ là làm cho nó dễ dàng tùy chỉnh, vì vậy nếu ai đó muốn một "phong cách" mới, thì khi đã quyết định xong trọng số của các chỉ số, sẽ mất chưa đến một phút để biến "phong cách mới" đó thành một lựa chọn.
Đối với mỗi vị trí, tôi quyết định một số xếp hạng mà tôi cho là quan trọng đối với cầu thủ ở vị trí đó. Ví dụ: các xếp hạng được quyết định cho vị trí hậu vệ cánh (Fulll/Wing-back) là: không chiến, tranh chấp tay đôi, chọn vị trí, dẫn bóng, chuyền bóng, sự tính tiến, sáng tạo, khả năng đe dọa khung thành và số phút thi đấu. Các xếp hạng này sau đó có trọng số khác nhau cho từng "phong cách" hậu vệ cánh.
Z-score được lấy từ dữ liệu cho từng chỉ số, điều này giúp xác định cầu thủ nào tốt hơn hay kém hơn đáng kể so với mức trung bình trong mỗi chỉ số. Mitrovic là một ví dụ điển hình về lý do tại sao Z-score có thể cung cấp nhiều ngữ cảnh hơn là "bách phân vị".


Mitrovic thể hiện ở phần trăm cao nhất cho chỉ số NPxG trên biểu đồ "pizza", điều này rất ấn tượng. Nhưng khi bạn nhìn vào biểu đồ "bầy ong" bên cạnh, bạn có thể thấy anh ấy tốt hơn bao nhiêu so với các đồng nghiệp của mình, điều này cung cấp thêm một chút bối cảnh về mức độ ấn tượng của anh ấy.
Tỷ lệ phân cấp (Percentile rank) không mang lại "sự công bằng" cho Mitrovic, đó là lý do tại sao Z-score rất hữu ích.
Số phút thi đấu được sử dụng trong xếp hạng và có trọng số 15% cho tất cả các vị trí và "phong cách". Điều này rất quan trọng vì ở kích thước mẫu, dữ liệu sẽ càng đáng tin cậy hơn khi cầu thủ chơi càng nhiều phút.
Công cụ này cũng loại bỏ những cầu thủ chưa chơi đủ số phút nhất định trước khi thực hiện bất kỳ tính toán nào, vì những cầu thủ có rất ít phút thi đấu có thể ảnh hưởng nặng nề đến Z-score.
Mục tiêu
Công cụ này được viết bằng ngôn ngữ Python. Một trong những mục tiêu khi tạo công cụ này là để nó hoạt động hiệu quả nhất có thể và tôi muốn nó được tự động hóa hết mức có thể với rất ít đầu vào cần thiết.
Hiện tại nó sẽ hỏi bạn: giải đấu, ví trí và mùa giải cần phân tích → nó sẽ tính toán Z-score và tính trọng số cho từng "phong cách" → nó hỏi bạn muốn xem "phong cách" nào và bất kỳ bộ lọc nào bạn muốn áp dụng, ví dụ: tuổi, giá trị, chân thuận v.v.
Sau đó, danh sách các cầu thủ cho vị trí và vai trò đó được sắp xếp từ tốt nhất đến kém nhất, kèm đính màu có điều kiện để giúp nhanh chóng xác định thời gian còn lại trong hợp đồng cho mỗi cầu thủ.
Sau đó, công cụ sẽ hỏi bạn có muốn xem "biểu đồ chỉ số" của một cầu thủ hay không, nếu có thì đó là cầu thủ nào và bạn muốn so sánh họ với cầu thủ khác hay mức trung bình → Sẽ xuất hiện một biểu đồ "radar", một biểu đồ "bầy ong" và hai biểu đồ "pizza" ngay lập tức để giúp xem các chỉ số mà cầu thủ vượt trội hoặc gặp khó khăn.
Và tất cả được thực hiện trong vòng chưa đến một phút với sự giúp sức của các công cụ xử lý dữ liệu lớn trên các nền tảng nổi tiếng như: Google Cloud, IBM Cloud, AWS, Azure..
Ví dụ cụ thể
Quay trở lại ví dụ ban đầu về việc nêu tên 3 hậu vệ cánh xuất sắc nhất ở giải National League (giải hạng 5 ở Anh) dưới 26 tuổi.
Với công cụ này, tôi có thể đưa ra danh sách 15 hậu vệ cánh (Full/Wing-back) dưới 26 tuổi của National League ngay lập tức, được liệt kê theo thứ tự mức độ phù hợp của họ với tìm kiếm "vị trí" hậu vệ cánh và "phong cách" toàn diện.

Màu của mỗi cầu thủ thể hiện thời gian còn lại trong hợp đồng của họ, trên thang từ xanh lục đến đỏ - xanh đậm là màu cho thấy cầu thủ đó sắp hết hợp đồng với CLB chủ quản (màu xanh nhạt thể hiện những cầu thủ chưa có thông tin về hợp đồng).
Cùng với danh sách, bạn có thể chọn một cầu thủ từ danh sách để xem "biểu đồ chỉ số". Tôi đã chọn thử cầu thủ được đánh giá cao nhất sắp hết hợp đồng là Michee Efete của Grimsby Town. Bốn hình ảnh dưới đây được tạo tự động, tổng quá trình chưa tới 45s.




Hai "biểu đồ pizza" đầu tiên dễ hiểu nhất, chúng hiển thị xếp hạng phần trăm, vì vậy nếu chỉ số trên thuộc tính đầy 3/4 hoặc hiển thị 75 thì bạn biết rằng người chơi nằm trong 25% người chơi hàng đầu cho chỉ số đó.
Biểu đồ "pizza" đầu tiên cung cấp tổng quan về các thuộc tính khác nhau mà không có chỉ số cụ thể, vì vậy bạn có thể quyết định rằng bạn muốn một hậu vệ cánh sáng tạo hơn thì Efete không phải là ưu tiên của bạn.
Biểu đồ "pizza" thứ hai cung cấp nhiều chỉ số cụ thể hơn, nó chia nhỏ một số thuộc tính thành các chỉ số hình thành chúng. Nó cho bạn biết rằng độ chính xác quả tạt của Efete rất kém và số quả tạt cũng như số đường kiến tạo dự kiến của anh ấy ở mức trung bình.
Biểu đồ "radar" đi vào chi tiết cụ thể hơn và trình bày dữ liệu thô của nhiều loại chỉ số hơn. Tuy nhiên, vì điểm tối thiểu và tối đa là điểm tối thiểu và tối đa của các cầu thủ trong tập dữ liệu, nên nó làm sai lệch hình dạng của điểm trung bình (được hiển thị bằng màu xanh lam). Do đó, khó phân tích nhanh cách một người chơi hoạt động trong từng chỉ số so với các cầu thủ có cùng vị trí với họ.
Biểu đồ "radar" cung cấp cho bạn những con số thô. Ví dụ: trên biểu đồ "pizza", bạn có thể nói rằng Efete đã thực hiện rất nhiều lần "chạy lũy tiến", anh ấy đang ở con số 81. Tuy nhiên, bạn không thể biết chỉ số đó là bao nhiêu, với biểu đồ "radar" bạn có thể thấy anh ấy thực hiện khoảng 2,5 lần mỗi 90 phút và con số này cao hơn mức trung bình của giải đấu đối với các hậu vệ cánh một cách đáng kể.
Cuối cùng, biểu đồ "bầy ong" hiển thị sự phân bố của cầu thủ qua các chỉ số nhất định. Chúng ta đã biết rằng Efete đang ở mức 81 về số lần "chạy lũy tiến" và anh ấy thực hiện được 2,5 lần trên 90 phút, bây giờ chúng ta có thể thấy trực tiếp điều này so với những cầu thủ khác trong giải đấu.
Mỗi hình ảnh cung cấp thêm một chút thông tin để xây dụng bức tranh tổng thế về điểm mạnh và điểm yếu của cầu thủ được tìm hiểu.
Sau đó, công cụ hỏi bạn có muốn so sánh cầu thủ đã chọn của mình với cầu thủ khác từ danh sách hay không, nếu bạn chọn 'không' thì nó sẽ tạo ra các hình ảnh hiển thị ở trên để so sánh cầu thủ được chọn với mức trung bình của giải đấu và sự phân bố các chỉ số của cầu thủ đó.
Nếu bạn chọn ‘có’ thì bạn sẽ nhận được hai biểu đồ "pizza" ban đầu, nhưng biểu đồ radar và biểu đồ "bầy ong" sẽ có chỉ số của cả hai cầu thủ với nhau với các màu khác nhau.


Một số vấn đề phát sinh
Hiện tại có hai vấn đề chính với công cụ, đó là:
Ví dụ, một cầu thủ chạy cánh chơi trong một đội sử dụng tiền vệ cánh rộng và có một mục tiêu trong vòng cấm để đánh đầu sẽ có nhiều quả tạt. Do đó, nếu bạn sử dụng số chỉ số tạt bóng mỗi 90 phút để phân tích cầu thủ thì cầu thủ đó sẽ trông rất "đẹp", tuy nhiên điều này không thể hiện quá nhiều ý nghĩa.
Các chỉ số về độ chính xác các quả tạt có thể giúp ích ở đây, tuy nhiên cầu thủ có thể tạt đủ số lần để tìm ra độ chính xác của họ tiệm cận đến con số nào. Ngoài ra, độ chính xác của các quả tạt bóng còn có các yếu tố khác ảnh hưởng đến nó: độ khó của tình huống tạt bóng, người nhận bóng, hậu vệ cánh trong tình huống đó là ai... (Điều này có thể kết hợp với ý tưởng về xếp hạng khả năng dẫn bóng của các cầu thủ mà DOUS giới thiệu ở kì trước).
Thật vậy kết hợp của rất nhiều bài toán nhỏ bạn sẽ vẽ lên một bức tranh lớn.
Tôi đã cố gắng hết sức để mang lại cái nhìn "công bằng" cho các chỉ số, chẳng hạn như số lần chuyền lũy tiến. Thay vì sử dụng số đường chuyền lũy tiến mỗi 90 phút, tôi sử dụng số đường chuyền lũy tiến mỗi 100 đường chuyền vì điều này giúp thể hiện những cầu thủ tốt chơi ở những đội không cầm nhiều bóng.
Dữ liệu này không "đặc biệt hữu ích" ở một số vị trí là một vấn đề liên quan đến việc phân tích dữ liệu trong tuyển trạch nói chung. Hậu vệ là ví dụ tốt nhất ở đây, và nó nói về các số liệu không phải là dự đoán hoặc đại diện cho chất lượng của một cầu thủ mà là nhiều hơn về những gì họ đã thể hiện, hoặc buộc phải thực hiện theo đội bóng.
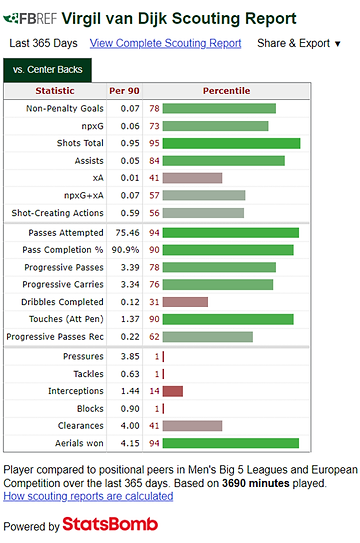 Virgil Van Dijk là một ví dụ điển hình ở đây, khi bạn nhìn vào biểu đồ chỉ số của anh ấy cho các chỉ số phòng thủ thì anh ấy trông thật tệ. Tuy nhiên, phần lớn điều này có thể ảnh hưởng bởi "phong cách" chơi tấn công và kiểm soát bóng của Liverpool, nghĩa là các hậu vệ không cần phải phòng thủ nhiều như những hậu vệ ở những đội bóng khác. Nó cũng thể được sự liên kết với vị trí và đọc tình huống tốt, nghĩa là không phải thực hiện nhiều hành động phòng thủ.
Virgil Van Dijk là một ví dụ điển hình ở đây, khi bạn nhìn vào biểu đồ chỉ số của anh ấy cho các chỉ số phòng thủ thì anh ấy trông thật tệ. Tuy nhiên, phần lớn điều này có thể ảnh hưởng bởi "phong cách" chơi tấn công và kiểm soát bóng của Liverpool, nghĩa là các hậu vệ không cần phải phòng thủ nhiều như những hậu vệ ở những đội bóng khác. Nó cũng thể được sự liên kết với vị trí và đọc tình huống tốt, nghĩa là không phải thực hiện nhiều hành động phòng thủ.
Những số liệu này đang mô tả những gì Van Dijk làm, chứ không phải là thực lực của anh ấy.
Vì vậy, tôi cũng nhận ra đó là một vấn đề và biết phải cân nhắc khi tôi thấy kết quả mà công cụ tạo ra.
Vấn đề thứ hai, đó không phải là vấn đề của công cụ, mà hơn thế nữa là kết quả của nó, là out-put của công cụ dựa vào dữ liệu in-put đầu vào. Tôi hiện đang sử dụng dữ liệu từ ..., đây là một nguồn tài nguyên tuyệt vời với giá cả tương đối phải chăng, tuy nhiên việc gắn thẻ các events đôi khi có thể sai.
Vì vậy mở rộng nhiều nguồn dữ liệu luôn là lựa chọn thông minh và đáng tin cậy hơn.
Cảm ơn những tác giả đã đóng góp cho bài viết này đặc biệt là Mr.AW..
Hãy đón chờ DOUS ở những phần tiếp theo… From Dous with Love !
― Sun Tzu, The Art of War
Tại sao sử dụng dữ liệu?
Quay trở lại với bóng đá thôi nào, dữ liệu là nguồn tài nguyên cực kỳ hữu ích cho các nhà tuyển trạch viên. Nó có thể cung cấp thông tin chi tiết mà bạn có thể không biết. Nếu bạn được yêu cầu nêu tên 3 trong số những hậu vệ cánh xuất sắc nhất ở National League (giải hạng 5 ở Anh) dưới 26 tuổi thì bạn có thể sẽ gặp khó khăn, nhưng với nguồn dữ liệu chất lượng và sử dụng tốt dữ liệu đó thì mọi việc trở nên dễ dàng hơn rất nhiều.
Bạn có thể nhanh chóng xây dựng danh sách cầu thủ phù hợp với mục tiêu tìm kiếm bằng cách sử dụng phân tích dữ liệu. Điều này có thể tiết kiệm rất nhiều thời gian để "xem giò" các cầu thủ, vì bạn đã có một danh sách chi tiết cấu thủ nào nên theo dõi, nó làm cho toàn bộ quá trình được "cô đặc" và hiệu quả hơn.
Lợi ích khác của việc sử dụng dữ liệu là nó giúp loại bỏ rất nhiều thành kiến. Các tuyển trạch viên có thể mắc phải những thành kiến này mà không nhận ra, họ có thể loại bỏ một cầu thủ dựa trên cách họ di chuyển, mặc dù cầu thủ đó có kết quả rất tốt.
Dữ liệu thì không mắc phải lỗi này vì nó không bị ảnh hưởng bởi cảm xúc. Tuy nhiên, các thành kiến có thể được xây dựng trong phân tích dữ liệu. Dữ liệu không bị sai lệch nhưng nhà phân tích dữ liệu có thể bị sai lệch.
Vì những lý do trên, tôi quyết định tạo ra một công cụ giúp tôi có cái nhìn "sâu hơn" về "phong cách" của một cầu thủ, điểm mạnh, điểm yếu của họ và cầu thủ nào phù hợp nhất với "phong cách" đó.
Phương pháp đánh giá
Quá trình xây dựng công cụ này là chia cầu thủ vào các vị trí khác nhau, sau đó chia họ thành nhiều "phong cách" khác nhau cho vị trí đó. Các vị trí và "phong cách" được hiển thị bên dưới:
Một trong những mục tiêu chính khi xây dựng công cụ là làm cho nó dễ dàng tùy chỉnh, vì vậy nếu ai đó muốn một "phong cách" mới, thì khi đã quyết định xong trọng số của các chỉ số, sẽ mất chưa đến một phút để biến "phong cách mới" đó thành một lựa chọn.
Đối với mỗi vị trí, tôi quyết định một số xếp hạng mà tôi cho là quan trọng đối với cầu thủ ở vị trí đó. Ví dụ: các xếp hạng được quyết định cho vị trí hậu vệ cánh (Fulll/Wing-back) là: không chiến, tranh chấp tay đôi, chọn vị trí, dẫn bóng, chuyền bóng, sự tính tiến, sáng tạo, khả năng đe dọa khung thành và số phút thi đấu. Các xếp hạng này sau đó có trọng số khác nhau cho từng "phong cách" hậu vệ cánh.
Z-score được lấy từ dữ liệu cho từng chỉ số, điều này giúp xác định cầu thủ nào tốt hơn hay kém hơn đáng kể so với mức trung bình trong mỗi chỉ số. Mitrovic là một ví dụ điển hình về lý do tại sao Z-score có thể cung cấp nhiều ngữ cảnh hơn là "bách phân vị".
Mitrovic thể hiện ở phần trăm cao nhất cho chỉ số NPxG trên biểu đồ "pizza", điều này rất ấn tượng. Nhưng khi bạn nhìn vào biểu đồ "bầy ong" bên cạnh, bạn có thể thấy anh ấy tốt hơn bao nhiêu so với các đồng nghiệp của mình, điều này cung cấp thêm một chút bối cảnh về mức độ ấn tượng của anh ấy.
Tỷ lệ phân cấp (Percentile rank) không mang lại "sự công bằng" cho Mitrovic, đó là lý do tại sao Z-score rất hữu ích.
Số phút thi đấu được sử dụng trong xếp hạng và có trọng số 15% cho tất cả các vị trí và "phong cách". Điều này rất quan trọng vì ở kích thước mẫu, dữ liệu sẽ càng đáng tin cậy hơn khi cầu thủ chơi càng nhiều phút.
Công cụ này cũng loại bỏ những cầu thủ chưa chơi đủ số phút nhất định trước khi thực hiện bất kỳ tính toán nào, vì những cầu thủ có rất ít phút thi đấu có thể ảnh hưởng nặng nề đến Z-score.
Mục tiêu
Công cụ này được viết bằng ngôn ngữ Python. Một trong những mục tiêu khi tạo công cụ này là để nó hoạt động hiệu quả nhất có thể và tôi muốn nó được tự động hóa hết mức có thể với rất ít đầu vào cần thiết.
Hiện tại nó sẽ hỏi bạn: giải đấu, ví trí và mùa giải cần phân tích → nó sẽ tính toán Z-score và tính trọng số cho từng "phong cách" → nó hỏi bạn muốn xem "phong cách" nào và bất kỳ bộ lọc nào bạn muốn áp dụng, ví dụ: tuổi, giá trị, chân thuận v.v.
Sau đó, danh sách các cầu thủ cho vị trí và vai trò đó được sắp xếp từ tốt nhất đến kém nhất, kèm đính màu có điều kiện để giúp nhanh chóng xác định thời gian còn lại trong hợp đồng cho mỗi cầu thủ.
Sau đó, công cụ sẽ hỏi bạn có muốn xem "biểu đồ chỉ số" của một cầu thủ hay không, nếu có thì đó là cầu thủ nào và bạn muốn so sánh họ với cầu thủ khác hay mức trung bình → Sẽ xuất hiện một biểu đồ "radar", một biểu đồ "bầy ong" và hai biểu đồ "pizza" ngay lập tức để giúp xem các chỉ số mà cầu thủ vượt trội hoặc gặp khó khăn.
Và tất cả được thực hiện trong vòng chưa đến một phút với sự giúp sức của các công cụ xử lý dữ liệu lớn trên các nền tảng nổi tiếng như: Google Cloud, IBM Cloud, AWS, Azure..
Ví dụ cụ thể
Quay trở lại ví dụ ban đầu về việc nêu tên 3 hậu vệ cánh xuất sắc nhất ở giải National League (giải hạng 5 ở Anh) dưới 26 tuổi.
Với công cụ này, tôi có thể đưa ra danh sách 15 hậu vệ cánh (Full/Wing-back) dưới 26 tuổi của National League ngay lập tức, được liệt kê theo thứ tự mức độ phù hợp của họ với tìm kiếm "vị trí" hậu vệ cánh và "phong cách" toàn diện.
Màu của mỗi cầu thủ thể hiện thời gian còn lại trong hợp đồng của họ, trên thang từ xanh lục đến đỏ - xanh đậm là màu cho thấy cầu thủ đó sắp hết hợp đồng với CLB chủ quản (màu xanh nhạt thể hiện những cầu thủ chưa có thông tin về hợp đồng).
Cùng với danh sách, bạn có thể chọn một cầu thủ từ danh sách để xem "biểu đồ chỉ số". Tôi đã chọn thử cầu thủ được đánh giá cao nhất sắp hết hợp đồng là Michee Efete của Grimsby Town. Bốn hình ảnh dưới đây được tạo tự động, tổng quá trình chưa tới 45s.
Hai "biểu đồ pizza" đầu tiên dễ hiểu nhất, chúng hiển thị xếp hạng phần trăm, vì vậy nếu chỉ số trên thuộc tính đầy 3/4 hoặc hiển thị 75 thì bạn biết rằng người chơi nằm trong 25% người chơi hàng đầu cho chỉ số đó.
Biểu đồ "pizza" đầu tiên cung cấp tổng quan về các thuộc tính khác nhau mà không có chỉ số cụ thể, vì vậy bạn có thể quyết định rằng bạn muốn một hậu vệ cánh sáng tạo hơn thì Efete không phải là ưu tiên của bạn.
Biểu đồ "pizza" thứ hai cung cấp nhiều chỉ số cụ thể hơn, nó chia nhỏ một số thuộc tính thành các chỉ số hình thành chúng. Nó cho bạn biết rằng độ chính xác quả tạt của Efete rất kém và số quả tạt cũng như số đường kiến tạo dự kiến của anh ấy ở mức trung bình.
Biểu đồ "radar" đi vào chi tiết cụ thể hơn và trình bày dữ liệu thô của nhiều loại chỉ số hơn. Tuy nhiên, vì điểm tối thiểu và tối đa là điểm tối thiểu và tối đa của các cầu thủ trong tập dữ liệu, nên nó làm sai lệch hình dạng của điểm trung bình (được hiển thị bằng màu xanh lam). Do đó, khó phân tích nhanh cách một người chơi hoạt động trong từng chỉ số so với các cầu thủ có cùng vị trí với họ.
Biểu đồ "radar" cung cấp cho bạn những con số thô. Ví dụ: trên biểu đồ "pizza", bạn có thể nói rằng Efete đã thực hiện rất nhiều lần "chạy lũy tiến", anh ấy đang ở con số 81. Tuy nhiên, bạn không thể biết chỉ số đó là bao nhiêu, với biểu đồ "radar" bạn có thể thấy anh ấy thực hiện khoảng 2,5 lần mỗi 90 phút và con số này cao hơn mức trung bình của giải đấu đối với các hậu vệ cánh một cách đáng kể.
Cuối cùng, biểu đồ "bầy ong" hiển thị sự phân bố của cầu thủ qua các chỉ số nhất định. Chúng ta đã biết rằng Efete đang ở mức 81 về số lần "chạy lũy tiến" và anh ấy thực hiện được 2,5 lần trên 90 phút, bây giờ chúng ta có thể thấy trực tiếp điều này so với những cầu thủ khác trong giải đấu.
Mỗi hình ảnh cung cấp thêm một chút thông tin để xây dụng bức tranh tổng thế về điểm mạnh và điểm yếu của cầu thủ được tìm hiểu.
Sau đó, công cụ hỏi bạn có muốn so sánh cầu thủ đã chọn của mình với cầu thủ khác từ danh sách hay không, nếu bạn chọn 'không' thì nó sẽ tạo ra các hình ảnh hiển thị ở trên để so sánh cầu thủ được chọn với mức trung bình của giải đấu và sự phân bố các chỉ số của cầu thủ đó.
Nếu bạn chọn ‘có’ thì bạn sẽ nhận được hai biểu đồ "pizza" ban đầu, nhưng biểu đồ radar và biểu đồ "bầy ong" sẽ có chỉ số của cả hai cầu thủ với nhau với các màu khác nhau.
Một số vấn đề phát sinh
Hiện tại có hai vấn đề chính với công cụ, đó là:
- Rất nhiều số liệu mang tính mô tả hơn là dự đoán.
- Dữ liệu có sẵn không hữu ích cho tất cả các vị trí.
Ví dụ, một cầu thủ chạy cánh chơi trong một đội sử dụng tiền vệ cánh rộng và có một mục tiêu trong vòng cấm để đánh đầu sẽ có nhiều quả tạt. Do đó, nếu bạn sử dụng số chỉ số tạt bóng mỗi 90 phút để phân tích cầu thủ thì cầu thủ đó sẽ trông rất "đẹp", tuy nhiên điều này không thể hiện quá nhiều ý nghĩa.
Các chỉ số về độ chính xác các quả tạt có thể giúp ích ở đây, tuy nhiên cầu thủ có thể tạt đủ số lần để tìm ra độ chính xác của họ tiệm cận đến con số nào. Ngoài ra, độ chính xác của các quả tạt bóng còn có các yếu tố khác ảnh hưởng đến nó: độ khó của tình huống tạt bóng, người nhận bóng, hậu vệ cánh trong tình huống đó là ai... (Điều này có thể kết hợp với ý tưởng về xếp hạng khả năng dẫn bóng của các cầu thủ mà DOUS giới thiệu ở kì trước).
Thật vậy kết hợp của rất nhiều bài toán nhỏ bạn sẽ vẽ lên một bức tranh lớn.
Tôi đã cố gắng hết sức để mang lại cái nhìn "công bằng" cho các chỉ số, chẳng hạn như số lần chuyền lũy tiến. Thay vì sử dụng số đường chuyền lũy tiến mỗi 90 phút, tôi sử dụng số đường chuyền lũy tiến mỗi 100 đường chuyền vì điều này giúp thể hiện những cầu thủ tốt chơi ở những đội không cầm nhiều bóng.
Dữ liệu này không "đặc biệt hữu ích" ở một số vị trí là một vấn đề liên quan đến việc phân tích dữ liệu trong tuyển trạch nói chung. Hậu vệ là ví dụ tốt nhất ở đây, và nó nói về các số liệu không phải là dự đoán hoặc đại diện cho chất lượng của một cầu thủ mà là nhiều hơn về những gì họ đã thể hiện, hoặc buộc phải thực hiện theo đội bóng.
Những số liệu này đang mô tả những gì Van Dijk làm, chứ không phải là thực lực của anh ấy.
Vì vậy, tôi cũng nhận ra đó là một vấn đề và biết phải cân nhắc khi tôi thấy kết quả mà công cụ tạo ra.
Vấn đề thứ hai, đó không phải là vấn đề của công cụ, mà hơn thế nữa là kết quả của nó, là out-put của công cụ dựa vào dữ liệu in-put đầu vào. Tôi hiện đang sử dụng dữ liệu từ ..., đây là một nguồn tài nguyên tuyệt vời với giá cả tương đối phải chăng, tuy nhiên việc gắn thẻ các events đôi khi có thể sai.
Vì vậy mở rộng nhiều nguồn dữ liệu luôn là lựa chọn thông minh và đáng tin cậy hơn.
Cảm ơn những tác giả đã đóng góp cho bài viết này đặc biệt là Mr.AW..
Hãy đón chờ DOUS ở những phần tiếp theo… From Dous with Love !