#WDIDT #2: Cập nhật tuần rồi của mình vừa qua thì chỉ mới đọc đc sơ sơ 1 survey paper thôi, do tình hình chống dịch căng thẳng quá

. Cơ mà về crawler thì mình đã hoàn thành rồi

Tình hình crawler như sau: Mất một thời gian suy nghĩ đi suy nghĩ lại thì mình tạm chọn mục f17 làm data. Và cũng có thể xem là nguồn data dồi dào nhất trong forum voz này. Tuy nhiên, cũng có 1 số hạn chế từ nguồn dữ liệu này, cái này chắc là mình sẽ nói sau khi đến phần phân tích dữ liệu.
Hy vọng được mấy bạn làm bên mảng phân tích data hỗ trợ

Cuối cùng, mong cán bộ bỏ qua hành vi này

nếu cán bộ ưng thì sau khi hoàn thành sản phẩm, mình sẽ trao lại toàn bộ source code mà mình làm nhé.
P/S: Chi tiết về crawler thì mình dùng thư viện scrapy và chi tiết spider mình đính kèm sau đây:
Python:
import scrapy
class VozSpider(scrapy.Spider):
name = 'voz'
start_urls = ['https://voz.vn/f/chuyen-tro-linh-tinh.17/']
custom_settings = { 'FEED_URI': "voz_%(time)s.json",
'FEED_FORMAT': 'json',
'FEED_EXPORT_ENCODING': 'utf-8'}
def parse(self, response):
print("Current URL: {}".format(response.url))
post_urls = response.xpath('//div[@class="structItem-title"]//a/@href').extract()
for url_item in post_urls:
yield scrapy.Request('https://voz.vn' + url_item, callback=self.content_parse)
next_page = response.xpath('//a[contains(@class, "pageNav-jump--next")]//@href').get()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
def content_parse(self, response):
yield {
'url': response.url,
'title': response.xpath('//h1[contains(@class, "p-title-value")]/text()').get().strip(),
'text': '[_SEP_]'.join(response.xpath('//article[@class="message-body js-selectToQuote"]//div[contains(@class, "bbWrapper")]/text()[not(ancestor::blockquote)]').extract()).strip(),
}
next_page = response.xpath('//a[contains(@class, "pageNav-jump--next")]//@href').get()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.content_parse)

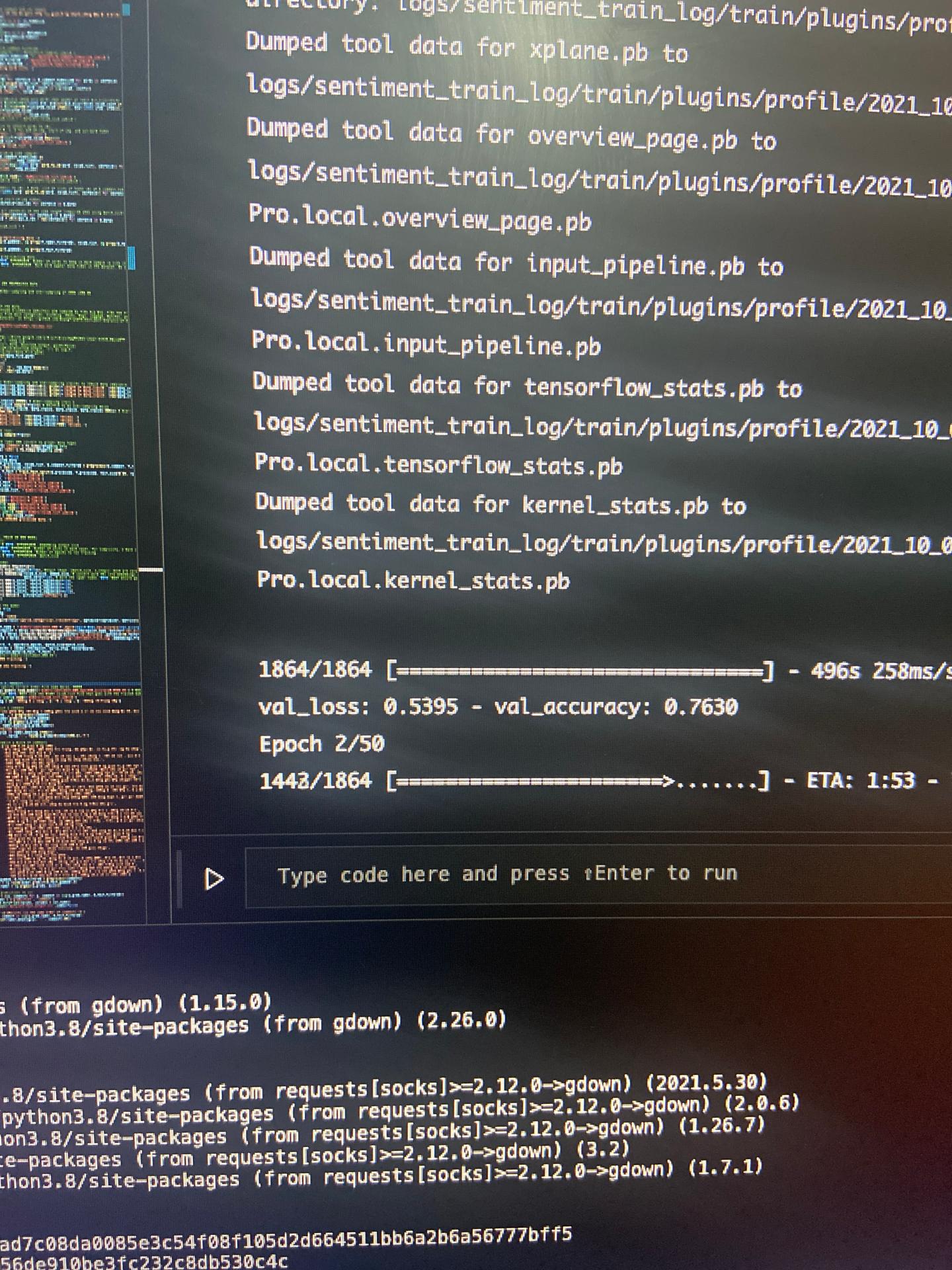
 mà thường train thì xài GPU cho nhanh nhỉ, bạn train chay như v thì lâu lắm
mà thường train thì xài GPU cho nhanh nhỉ, bạn train chay như v thì lâu lắm