
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
kiến thức Tổng hợp những addon chất cho Firefox / Chromium
- Thread starter toi la gay :sosad:
- Start date

Submain
Senior Member
Các thím ơi, có thím nào rành firefox biết cách tải chương mấy trang kiểu này không ạ
 .
.
Hình như nó còn không cho chuột phải, xem mã nguồn nữa

Hình như nó còn không cho chuột phải, xem mã nguồn nữa
toi la gay :sosad:
Senior Member
Dùng cái bookmarklet này:Các thím ơi, có thím nào rành firefox biết cách tải chương mấy trang kiểu này không ạ.
Hình như nó còn không cho chuột phải, xem mã nguồn nữa
- Tool biến code Javascript thành Bookmarklets
- Đọc nội dung web
- Phá bỏ giới hạn chống copy, chuột phải của trang web (dùng tool biến Bookmarklets bên trên)

NoPaste - No-database paste service
NoPaste is a client-side paste service which works with no database, and no back-end code. The data is stored entirely in the links and nowhere else
Là sẽ bôi đen được, còn muốn chuột phải giữ chặt Shift, đó là lợi thế của dòng Firefox so với Chrome, nút Shift = phá bỏ xiêng xích bà Tuyết Đai Mần.
Kết ezpz nhé:
toi la gay :sosad:
Senior Member
Vịt pede bê đê hơn MDM, cái kém duy nhất là nó không phải là một phần của trình duyệt thôi nên nó bị TLS Fingerprint cấm hotlink kiểu tinh xảo nhất hiện tại, còn MDM thì không hề vì TLS y hệt 1:1 Firefox, mà cái này phải hỏi ngài @shenzero999, trùm sò, Columbus pede chuyên dùng con vịt tải luật từ nước Ba Tư về truyền thụ cho dân đen.con vịt so với MDM thì như thế nào các bác
Thermophilic.Bacteria
Senior Member
Tải chương thì có Single File, lưu hết về 1 file rồi có thể chuyển sang PDF cho tiệnCác thím ơi, có thím nào rành firefox biết cách tải chương mấy trang kiểu này không ạ.
Hình như nó còn không cho chuột phải, xem mã nguồn nữa

SingleFile - Nhận tiện ích mở rộng này cho 🦊 Firefox (vi)
Tải xuống SingleFile cho Firefox. Save an entire web page—including images and styling—as a single HTML file.
Submain
Senior Member
toi la gay :sosad:
Senior Member
Nói chung là hiện ý tưởng là muốn tự động hay là lưu tay ?Thế trường hợp cái danh sách chương nó như thế này thì giải quyết sao thím. @toi la gay :sosad:
.
View attachment 2182858
Trang này nó mã hóa chữ, nên dễ dàng nhất là dùng addon tự động hóa như UI.vision hay Automa ở #1 rồi viết luật cho nó tự động tải từng chương một là dễ nhất, còn nếu biết lập trình tự động hóa thì dùng Python+selenium/BeautifulSoup cào cả trang nó về máy.
Nếu ngắn thì cứ lưu tay thôi, dùng cái script nào đó ngài @Fioren từng chia sẻ cho chạy ở trang đó rồi bôi đen mà lưu tay.
Submain
Senior Member
tự động đi thím. Em cài được python rồi. Khổ cái là trang này nó bị vụ bản quyền + mã hoá chữ ghê quá.Nói chung là hiện ý tưởng là muốn tự động hay là lưu tay ?
Trang này nó mã hóa chữ, nên dễ dàng nhất là dùng addon tự động hóa như UI.vision hay Automa ở #1 rồi viết luật cho nó tự động tải từng chương một là dễ nhất, còn nếu biết lập trình tự động hóa thì dùng Python+selenium/BeautifulSoup cào cả trang nó về máy.
Nếu ngắn thì cứ lưu tay thôi, dùng cái script nào đó ngài @Fioren từng chia sẻ cho chạy ở trang đó rồi bôi đen mà lưu tay.

Em chỉ cần vượt qua bước bản quyền của nó rồi cào về python cũng được
toi la gay :sosad:
Senior Member
Cài selenium, dùng geckodrive rồi cho nó chạy qua Firefox là ok, dùng Shift Inspect sẽ ra cái ID chứa chữ làtự động đi thím. Em cài được python rồi. Khổ cái là trang này nó bị vụ bản quyền + mã hoá chữ ghê quá.
Em chỉ cần vượt qua bước bản quyền của nó rồi cào về python cũng được
id_chap_content, phần còn lại tự mò nhé, bởi tự động hóa thì kinh nghiệm >>> tất cả, cứ từ từ xây dựng kinh nghiệm rồi sẽ thành một bờ dồ.kjllmeplz
Senior Member
nhớ có 1 cái script down từ truyenyy convert sang epub, bác có thể tìm và và sửa lại để dùng được trên bns

Submain
Senior Member
Thanks bro. Cái vụ mã hoá chữ ấy, bro có keyword cho vụ này không?.Cài selenium, dùng geckodrive rồi cho nó chạy qua Firefox là ok, dùng Shift Inspect sẽ ra cái ID chứa chữ làid_chap_content, phần còn lại tự mò nhé, bởi tự động hóa thì kinh nghiệm >>> tất cả, cứ từ từ xây dựng kinh nghiệm rồi sẽ thành một bờ dồ.
Trang này đúng như bro nói. Nó mã hoá như thế này
Quả jkiêj, xậu mkáv kiệj hộv vsojn jkữjn vay xkâj xủa Pojv Betje đajn jấm ở tau kàjn xây gajk, quaj táv jnười đi đườjn dui với.
Submain
Senior Member
Nó dính mấy trang phải mua vip thì phải bronhớ có 1 cái script down từ truyenyy convert sang epub, bác có thể tìm và và sửa lại để dùng được trên bns

toi la gay :sosad:
Senior Member
Cơ mà chưa hiểu trang này nó hoạt động ra sao, nghĩa là nó không giải mã hóa kể cả khi xem bằng trình duyệt mà phải có tài khoản VIP hay là trang bị lỗi ?Thanks bro. Cái vụ mã hoá chữ ấy, bro có keyword cho vụ này không?.
Trang này đúng như bro nói. Nó mã hoá như thế này
Bởi nếu trình duyệt giải mã hóa qua Javascript thì selenium kéo trong 1 nốt nhạc.
Submain
Senior Member
Trang này mình chịu vì ít khi đọc trang này lắm.Cơ mà chưa hiểu trang này nó hoạt động ra sao, nghĩa là nó không giải mã hóa kể cả khi xem bằng trình duyệt mà phải có tài khoản VIP hay là trang bị lỗi ?
Bởi nếu trình duyệt giải mã hóa qua Javascript thì selenium kéo trong 1 nốt nhạc.
Mình để ý là nó không cho xem mã nguồn.
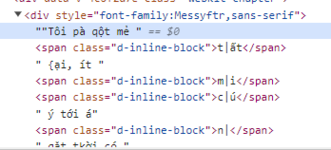
À mình có dùng cái extension SingleFile của thím phía trên để down, thì đến đây rồi. Mình nghĩ tới vụ dùng python3, extract <div style="font-messy"> ra từng dòng
Ví dụ:
HTML:
<div style="font-messy">
"Cta mẹ rôi <span class="d-inline-block">}tông</span> rtể tỗ rkợ <span class="d-inline-block">|to</span> rôi, lằng <span class="d-inline-block">|ấv</span> <span class="d-inline-block">|ủa</span> rôi <span class="d-inline-block">|ũng</span> <span class="d-inline-block">}tông</span> <span class="d-inline-block">|ao,</span> xẻ xoi mộr mìnt rìm <span class="d-inline-block">}iếm</span> rương xai ở rkong rtànt rtị.
</div>Rồi từ đó tìm cách đối phó với mã hoá text
Attachments
toi la gay :sosad:
Senior Member
Nếu hiểu nguyên lý của cách nó mã hóa (quan trọng nhất) thì có thể viết userscript giải mã hóa thành dạng thường rồi kéo về, khi đó có thể kết hợp thêm selenium tự động hóa.Trang này mình chịu vì ít khi đọc trang này lắm.
Mình để ý là nó không cho xem mã nguồn.
À mình có dùng cái extension SingleFile của thím phía trên để down, thì đến đây rồi. Mình nghĩ tới vụ dùng python3, extract <div style="font-messy"> ra từng dòng
Ví dụ:
HTML:<div style="font-messy"> "Cta mẹ rôi <span class="d-inline-block">}tông</span> rtể tỗ rkợ <span class="d-inline-block">|to</span> rôi, lằng <span class="d-inline-block">|ấv</span> <span class="d-inline-block">|ủa</span> rôi <span class="d-inline-block">|ũng</span> <span class="d-inline-block">}tông</span> <span class="d-inline-block">|ao,</span> xẻ xoi mộr mìnt rìm <span class="d-inline-block">}iếm</span> rương xai ở rkong rtànt rtị. </div>
View attachment 2182914
Rồi từ đó tìm cách đối phó với mã hoá tex
Submain
Senior Member
Thím giúp mình đoạn này bằng python3 được khôngNếu hiểu nguyên lý của cách nó mã hóa (quan trọng nhất) thì có thể viết userscript giải mã hóa thành dạng thường rồi kéo về, khi đó có thể kết hợp thêm selenium tự động hóa.

toi la gay :sosad:
Senior Member
Đưa mình link test thử rồi sẽ báo kết quả.bác nào biết cách tắt cái thanh trạng thái trên Firefox android không, dùng fullscreen mà nó hiện cái này ngu thật sự. Nhảy sang chrome test thử thì không bịView attachment 2182927
Lỗi này có thể tùy từng hệ điều hành Android, trên Google Pixel thì không hề có hiện tượng này nếu là xem Youtube và đa phần trang khác, bởi Android còn có nhiều bản mod của nhiều công ty.
toi la gay :sosad:
Senior Member
Đọc hướng dẫn là tường hết thôi:Thím giúp mình đoạn này bằng python3 được không
- Cài sẵn addon và script cho Firefox selenium, cách đơn giản nhất là ép Selenium nó dùng profile đã cài sẵn Violentmonkey và script: How to install extension permanently in geckodriver (https://stackoverflow.com/questions/54754945/how-to-install-extension-permanently-in-geckodriver)
- Tìm element trên trang, lấy dữ liệu: 4. Locating Elements — Selenium Python Bindings 2 documentation (https://selenium-python.readthedocs.io/locating-elements.html)
Similar threads
- Replies
- 0
- Views
- 116
- Replies
- 10
- Views
- 614
- Replies
- 0
- Views
- 202
- Replies
- 237
- Views
- 21K