
sirhung1993
Người qua đường
Chào mọi người, trong thread này mình tập trung làm rõ về các khái niệm hay được dùng để chỉ về việc xử lý song song như multi-threading, concurrency, parallelism hoặc asynchronous / non-blocking IO.
Mình hiện tại thì làm Data Engineer, công việc thường ngày hay phải xử lý những batch data lớn, nên có cơ hội được vọc vạch nhiều vào thư java.util.concurrent.* . Kiến thức trong bài sẽ được lấy từ cách mình triển khai trong Java ( có kết hợp so sánh với Go-lang vs C++) và 1 phần trích dẫn từ quyển Advanced Programming in the UNIX Environment, 3rd Edition.
Về phần Async/non-blocking IO thì sẽ lấy ví dụ từ NodeJS vs Java Quarkus. ( tại sao phần này lại liên quan đến xử lý song song thì sẽ giải thích sau)
Các topic chính:
1. Hardware
Đây là lầm tưởng nhiều người mắc phải nhất khi nói về multi-threading/concurrency programming .
Không nhất thiết hardware phải nhiều core và nhiều thread (đôi khi là memory) để support việc lập trình multi-threading/concurrency . Tuy nhiên, hardware có nhiều core/thread/memory thì sẽ ảnh hưởng tới performance, nhưng không quá ảnh hưởng đến cách software được phát triển.
Phần processes/threads đã được trừu tượng hóa ở OS , nên code không phải quan tâm nhiều đến việc hardware có support multi-thread hay không.
Để hiểu hơn khái niệm concurrency vs multi-threading, mình giới thiệu 1 tí về cách hardware chạy machine code.
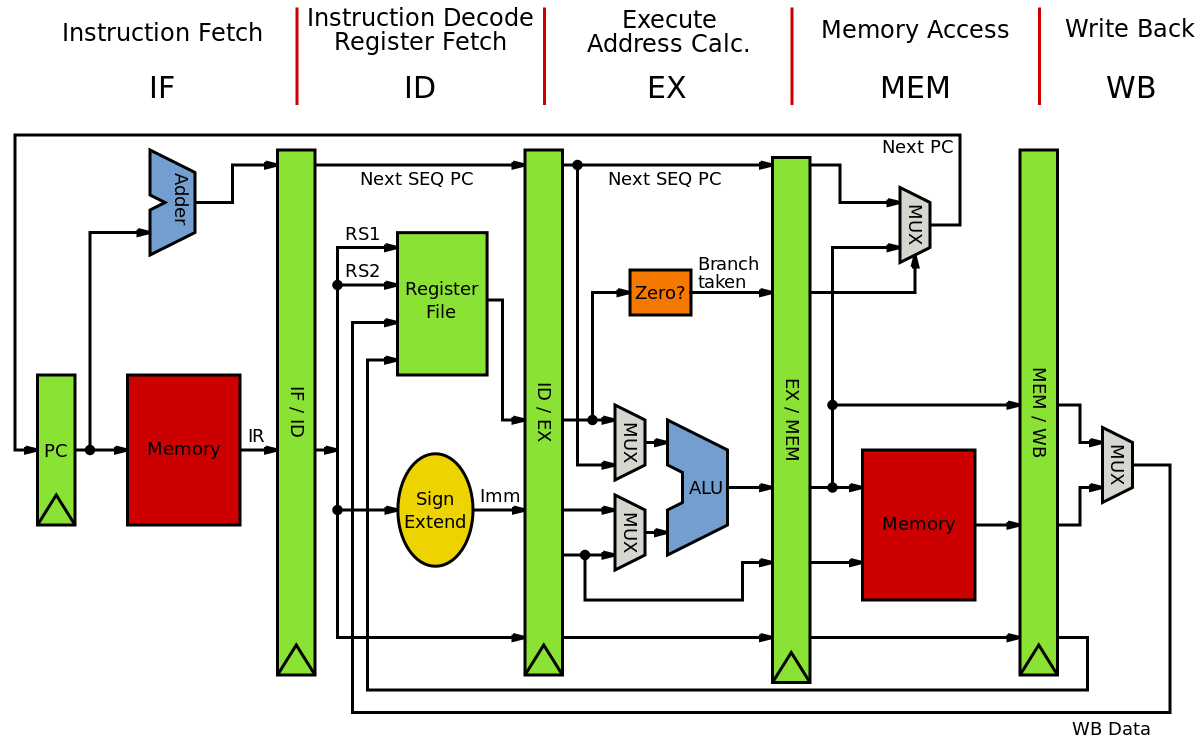
(Nguồn wiki _ MIPS architecture)
Lấy kiến trúc MIPS làm ví dụ cho đơn giản, thì 1 core có 2 bộ phận chính là Program Counter(PC) và Arithmetic Logic Unit (ALU) .
Và pipe-line có 5 stage ( IF/ID/EX/MEM/WB) .
Giả sử ta chỉ có 1 core như hình, thì việc multi-threading/parallel là không support ở hardware. Nhưng concurrency thì có thể.
Tức là với pipe-line có 5 stages, thì đôi khi 1 số stage bị block bởi việc access-memory, thì 1 core vẫn chạy ở những stages khác.
Về lý thuyết nó có thể chạy 1 lúc 5 tasks.
Số stages của pipe-line ảnh hưởng rất lớn tới performance của CPU, nhưng hạn chế của nó là làm tăng độ phức tạp của tập lệnh (ISA - instruction set architecture). Lấy ví dụ như x86 là 1 tập lệnh CISC (complex Instruction Set Computer) , đối lập với MIPS và ARM thuộc RISC (Reduced ISC). CPU x86 của Intel vs AMD có tới vài chục stages hoặc hơn.
Số stages càng nhiều, đại diện cho khả năng concurrency của hardware . Số core/thread càng nhiều, đại diện cho khả năng multi-thread/parallelism .
Nghĩa là kể cả chỉ có 1 core/thread, thì mình vẫn chạy được code 1 cách concurrency .
Chưa kể những bộ phận bí mật của Intel/AMD như branch-prediction / fetch-prediction / direct memory access còn làm tăng khả năng concurrency lên rất nhiều.
Tới đây thì các dev cũng đừng quá lo vì quá nhiều keyword, vì OS đã abstract hầu hết đặc tính của hardware. Việc của dev chỉ là dùng thư viện support concurrency/multi-thread.
Mình hiện tại thì làm Data Engineer, công việc thường ngày hay phải xử lý những batch data lớn, nên có cơ hội được vọc vạch nhiều vào thư java.util.concurrent.* . Kiến thức trong bài sẽ được lấy từ cách mình triển khai trong Java ( có kết hợp so sánh với Go-lang vs C++) và 1 phần trích dẫn từ quyển Advanced Programming in the UNIX Environment, 3rd Edition.
Về phần Async/non-blocking IO thì sẽ lấy ví dụ từ NodeJS vs Java Quarkus. ( tại sao phần này lại liên quan đến xử lý song song thì sẽ giải thích sau)
Các topic chính:
- Ảnh hưởng của hardware đến việc multi-threading
- OS có ảnh hưởng gì đến việc multi-threading
- Async/non-blocking IO được implement như thế nào ?
- Vai trò của lambda function vs functional programming trong Async/non-blocking IO và multi-threading
- NodeJS không chạy multi-thread được ? (controversial/thảo luận))
- Race-condition, thread-safe và cách nhận biết
- Demo Thread vs ThreadPool trong Java và các cấu trúc dữ liệu hay dùng ( tất nhiên là phải thread-safe)
- Ví dụ : web-framework xử lý http-request (Quarkus - event-loop and worker-pool)
1. Hardware
Đây là lầm tưởng nhiều người mắc phải nhất khi nói về multi-threading/concurrency programming .
Không nhất thiết hardware phải nhiều core và nhiều thread (đôi khi là memory) để support việc lập trình multi-threading/concurrency . Tuy nhiên, hardware có nhiều core/thread/memory thì sẽ ảnh hưởng tới performance, nhưng không quá ảnh hưởng đến cách software được phát triển.
Phần processes/threads đã được trừu tượng hóa ở OS , nên code không phải quan tâm nhiều đến việc hardware có support multi-thread hay không.
Để hiểu hơn khái niệm concurrency vs multi-threading, mình giới thiệu 1 tí về cách hardware chạy machine code.
(Nguồn wiki _ MIPS architecture)
Lấy kiến trúc MIPS làm ví dụ cho đơn giản, thì 1 core có 2 bộ phận chính là Program Counter(PC) và Arithmetic Logic Unit (ALU) .
Và pipe-line có 5 stage ( IF/ID/EX/MEM/WB) .
Giả sử ta chỉ có 1 core như hình, thì việc multi-threading/parallel là không support ở hardware. Nhưng concurrency thì có thể.
Tức là với pipe-line có 5 stages, thì đôi khi 1 số stage bị block bởi việc access-memory, thì 1 core vẫn chạy ở những stages khác.
Về lý thuyết nó có thể chạy 1 lúc 5 tasks.
Số stages của pipe-line ảnh hưởng rất lớn tới performance của CPU, nhưng hạn chế của nó là làm tăng độ phức tạp của tập lệnh (ISA - instruction set architecture). Lấy ví dụ như x86 là 1 tập lệnh CISC (complex Instruction Set Computer) , đối lập với MIPS và ARM thuộc RISC (Reduced ISC). CPU x86 của Intel vs AMD có tới vài chục stages hoặc hơn.
Số stages càng nhiều, đại diện cho khả năng concurrency của hardware . Số core/thread càng nhiều, đại diện cho khả năng multi-thread/parallelism .
Nghĩa là kể cả chỉ có 1 core/thread, thì mình vẫn chạy được code 1 cách concurrency .
Chưa kể những bộ phận bí mật của Intel/AMD như branch-prediction / fetch-prediction / direct memory access còn làm tăng khả năng concurrency lên rất nhiều.
Tới đây thì các dev cũng đừng quá lo vì quá nhiều keyword, vì OS đã abstract hầu hết đặc tính của hardware. Việc của dev chỉ là dùng thư viện support concurrency/multi-thread.
Last edited:
 ).
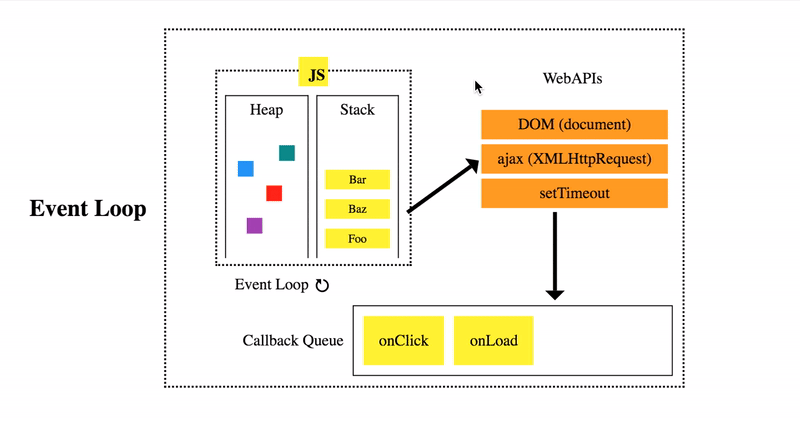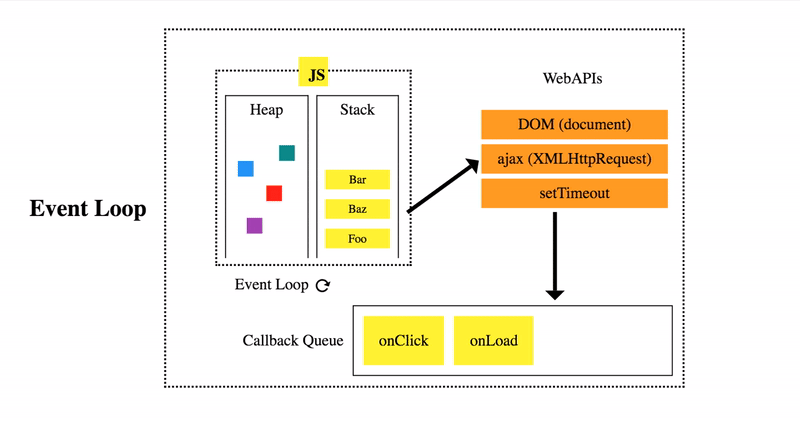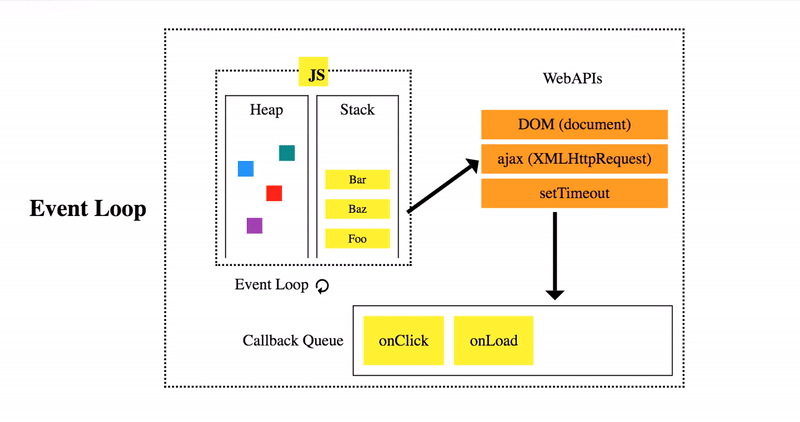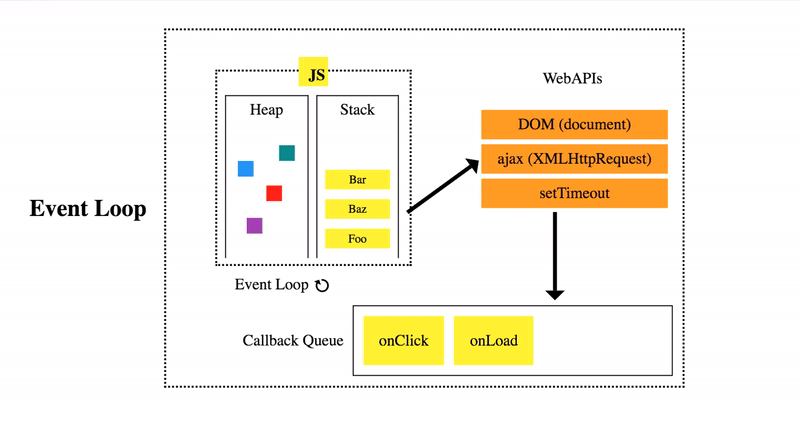
).

 E xin thêm book hoặc course tiếng anh để bổ sung kiến thức ạ
E xin thêm book hoặc course tiếng anh để bổ sung kiến thức ạ