
cuuduongthancong.com
Senior Member

Chào các bạn,
Ngày nay website vẫn đóng vai trò quan trọng trong việc giới thiệu sản phẩm tới người dùng. Ví dụ các công ty lớn như Amazon, Thế giới di động, Shopee, Tiki,... đều có website để tiếp cận khách hàng. Việc phát triển website đã khó tuy nhiên việc quảng bá website đến khách hàng cũng khó không kém. Hôm nay tôi xin được giới thiệu với các bạn kiến thức cơ bản để có thể giúp website hiện diện tốt hơn trên kết quả của các công cụ tìm kiếm như Google.
Nội dung
- Giói thiệu Search Engine Optimize
- B1) Crawling
- B2) Indexing
- B3) Serving (and ranking)
- Nhận xét
- Tài liệu tham khảo
Giới Thiệu Về Search Engine
- Search engine là một công cụ giúp con người tìm các kiếm nội dung trên internet. Google Search, hay ngắn gọi Google, là một search engine được phát triển bởi Google. Hiện nay google chiếm phần lớn thị phần tìm kiếm nên trong bài viết này chỉ đề cập đến Google
- Search Engine Optimize (SEO) là quá trình làm cho website có vị trí tốt hơn trong kết quả của Search Engine
- Tại sao cần phải thực hiện SEO? Bởi vì có vị trí cao trên kết quả tìm kiếm sẽ giúp tiếp cận nhiều người dùng/khách hàng hơn từ đó có cơ hội mang lại nhiều lợi nhuận hơn. Vị trí cao trên kết quả tìm kiếm cũng thẻ hiện được uy tín của website vì được Search Engine đánh giá cao
- Có 3 bước cơ bản từ lúc Google thu thập kết quả đến lúc trả về kết quả tìm kiếm cho người dùng là B1) Crawling, B2) Indexing, B3) Serving (and ranking)
- Điều kiện cần để 1 trang web có thể xuất hiện trong kết quả tìm kiếm của google là trang web phải được xử lý đến bước 2. Còn việc xuất hiện ở bước 3 hay không thì còn phụ thuộc vào chật lượng nội dung trang web và thuật toán của Google.
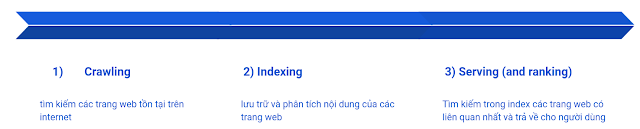
B1) Crawling
Google dùng 1 số lượng lớn các máy tính để crawl các trang web trên internet. Chương trình dùng để crawl các trang web này gọi là Google Bot (sau đây có thể gọi ngắn gọn là Google). Trong quá trình crawl, Google sẽ dùng các phiên bản mới của Google Chrome để render nội dung các trang web. Google cũng có thể chạy các đoạn code javascript có trên trang web.Làm sao Google biết các URL nào để crawl?
- Các URL được liên kết bởi các trang web đã crawl trước đó
- Các URL được cung cấp bởi người quản trị thông qua sitemap hoặc cung cấp trên "Google Search Console" .
Các URL nào sẽ không được crawl?
- Các URL bị chặn trong file robots.txt
- Các URL đòi hỏi phản cung cấp thông tin đăng nhập, hoặc không truy xuất trực tiếp từ internet được
Cải thiện quá trình crawling đối với trang web
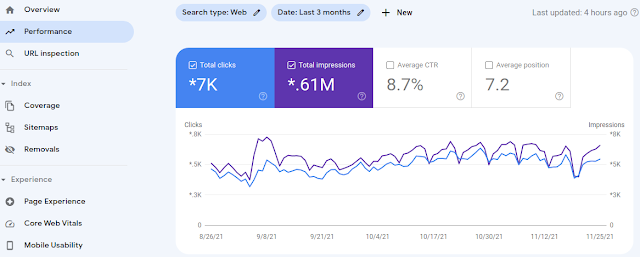
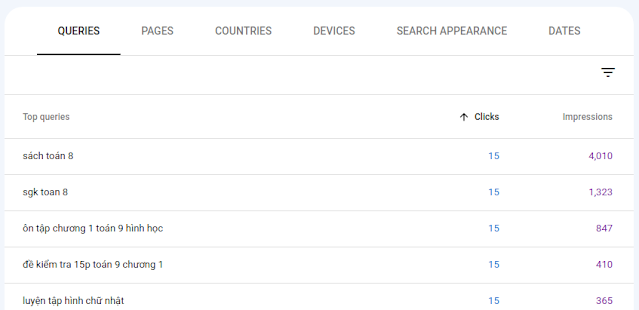
Google cung cấp công cụ Google Seach Console để người quản trị trang web xem thông tin và thực hiện các thông tin liên quan B1), B2), B3). Dựa vào báo cáo của Google có thể biết thời gian, tần suất, số lượng URL, lỗi,... trong quá trình crawl.
Mội số công việc để cải thiện, kiểm tra quá trình crawl
- Kiểm tra log trên server để biết nguyên nhân và sửa lỗi (nếu có)
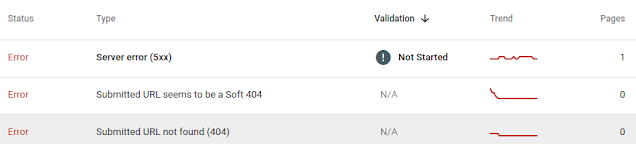
- Cung cấp thông tin sitemap để Google biết các URL trên trang web của bạn. Nếu để thuận theo tự nhiên thì có thể cần nhiều thời gian Google mới phát hiện hết các URL trên trang của bạn, nếu cung cấp thì Google có thể crawl nội dung sớm hơn
- Nếu trang web của bạn có bài viết mới thì có thể cung cấp từng url riêng lẻ để Google crawl ngay lập tức (nhưng không đảm bảo sẽ được index)
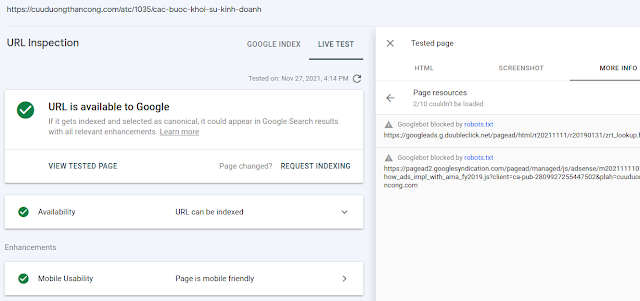
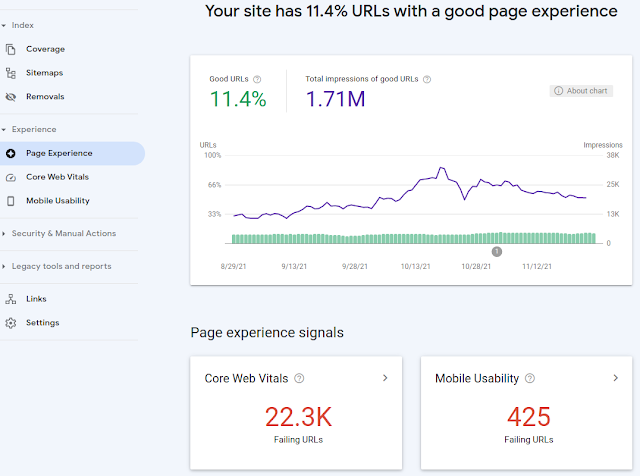
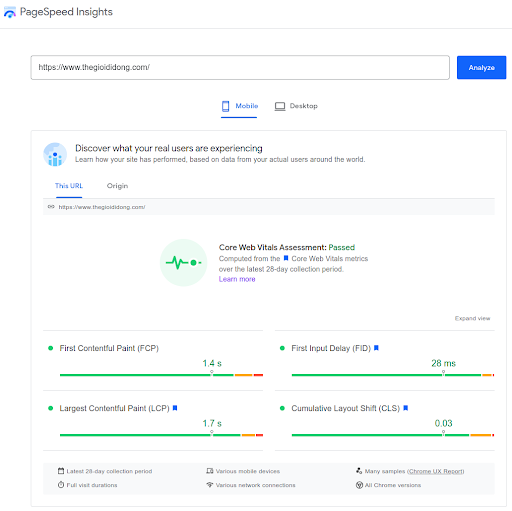
- Dùng "URL inspect tool" để kiểm tra xem Google có thể truy cập trang web thành công hay chưa, có lỗi tải các file tĩnh như hình ảnh, js, css hay không ( tab MORE INFO trên hình bên dưới). Đồng thời kiểm tra xem Google có render đúng như người dùng nhìn thấy không (tab SCREENSHOT). Nếu có lỗi ở bước này có thể ảnh hưởng đến việc Google hiểu sai nội dung từ đó đánh giá thấp nội dung trang web.






") )
)